
Jina AI commited on
Commit ·
2b230c9
0
Parent(s):
Initial public release
Browse files- .gitattributes +37 -0
- README.md +260 -0
- adapters/classification/adapter_config.json +39 -0
- adapters/classification/adapter_model.safetensors +3 -0
- adapters/clustering/adapter_config.json +39 -0
- adapters/clustering/adapter_model.safetensors +3 -0
- adapters/retrieval/adapter_config.json +39 -0
- adapters/retrieval/adapter_model.safetensors +3 -0
- adapters/text-matching/adapter_config.json +39 -0
- adapters/text-matching/adapter_model.safetensors +3 -0
- architecture.png +3 -0
- chat_template.jinja +154 -0
- config.json +101 -0
- config_sentence_transformers.json +8 -0
- custom_st.py +990 -0
- model.safetensors +3 -0
- modeling_jina_embeddings_v5_omni.py +616 -0
- modeling_llava_eurobert_audio.py +400 -0
- modules.json +8 -0
- preprocessor_config.json +24 -0
- processing_llava_eurobert.py +65 -0
- processor_config.json +68 -0
- tokenizer.json +3 -0
- tokenizer_config.json +23 -0
- video_preprocessor_config.json +29 -0
- vllm_jina_v5_omni.py +175 -0
- vllm_llava_eurobert_audio.py +889 -0
.gitattributes
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
architecture.png filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,260 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
pipeline_tag: sentence-similarity
|
| 3 |
+
tags:
|
| 4 |
+
- embedding
|
| 5 |
+
- jina-embeddings-v5
|
| 6 |
+
- feature-extraction
|
| 7 |
+
- sentence-transformers
|
| 8 |
+
- multimodal
|
| 9 |
+
- vision
|
| 10 |
+
- audio
|
| 11 |
+
- vllm
|
| 12 |
+
language:
|
| 13 |
+
- multilingual
|
| 14 |
+
inference: false
|
| 15 |
+
license: cc-by-nc-4.0
|
| 16 |
+
library_name: transformers
|
| 17 |
+
---
|
| 18 |
+
|
| 19 |
+
### **jina-embeddings-v5-omni-nano**: Multi-Task Omni Embedding Base (Nano)
|
| 20 |
+
|
| 21 |
+

|
| 22 |
+
|
| 23 |
+
### Model Overview
|
| 24 |
+
|
| 25 |
+
`jina-embeddings-v5-omni-nano` is a multimodal embedding model that accepts **text, images, video, and audio** and produces embeddings in a shared vector space aligned with the text-only [`jinaai/jina-embeddings-v5-text-nano`](https://huggingface.co/jinaai/jina-embeddings-v5-text-nano) — so you can index with text and query with any modality, no reindexing.
|
| 26 |
+
|
| 27 |
+
This is the **base** repository — it holds all task adapters (retrieval, classification, clustering, text-matching). For a single task, pre-merged task-specific variants are also available:
|
| 28 |
+
- [`jinaai/jina-embeddings-v5-omni-nano-classification`](https://huggingface.co/jinaai/jina-embeddings-v5-omni-nano-classification)
|
| 29 |
+
- [`jinaai/jina-embeddings-v5-omni-nano-clustering`](https://huggingface.co/jinaai/jina-embeddings-v5-omni-nano-clustering)
|
| 30 |
+
- [`jinaai/jina-embeddings-v5-omni-nano-retrieval`](https://huggingface.co/jinaai/jina-embeddings-v5-omni-nano-retrieval)
|
| 31 |
+
- [`jinaai/jina-embeddings-v5-omni-nano-text-matching`](https://huggingface.co/jinaai/jina-embeddings-v5-omni-nano-text-matching)
|
| 32 |
+
|
| 33 |
+
| Feature | Value |
|
| 34 |
+
| --- | --- |
|
| 35 |
+
| Parameters | ~1.04B |
|
| 36 |
+
| Embedding Dimension | 768 |
|
| 37 |
+
| Supported Tasks | `retrieval`, `classification`, `clustering`, `text-matching` |
|
| 38 |
+
| Max Sequence Length | 8192 |
|
| 39 |
+
| Pooling Strategy | Last-token |
|
| 40 |
+
| Supported Inputs | text, image, video, audio |
|
| 41 |
+
| Supported File Types | images: `.jpg`, `.jpeg`, `.png`, `.gif`, `.webp`, `.bmp`, `.tif`, `.tiff`, `.avif`, `.heic`, `.svg`; video: `.mp4`, `.avi`, `.mov`, `.mkv`, `.webm`, `.flv`, `.wmv`; audio: `.wav`, `.mp3`, `.flac`, `.ogg`, `.m4a`, `.opus`; documents: `.pdf` |
|
| 42 |
+
|
| 43 |
+
### Install
|
| 44 |
+
|
| 45 |
+
```bash
|
| 46 |
+
# core
|
| 47 |
+
pip install transformers torch pillow numpy
|
| 48 |
+
|
| 49 |
+
# Optional — install only the extras for the modalities you actually use:
|
| 50 |
+
pip install librosa soundfile # audio decoding
|
| 51 |
+
pip install av imageio # video decoding (pure-Python, no codec daemon)
|
| 52 |
+
pip install pdf2image pypdfium2 # PDF rendering
|
| 53 |
+
pip install cairosvg pillow # SVG rendering
|
| 54 |
+
pip install "vllm==0.20.1" # high-throughput serving (validated)
|
| 55 |
+
pip install sentence-transformers # one-call multimodal API
|
| 56 |
+
```
|
| 57 |
+
|
| 58 |
+
For minimum versions see the Requirements section below (transformers >= 4.57, torch >= 2.5; vLLM path validated with vllm == 0.20.1).
|
| 59 |
+
|
| 60 |
+
### Quickstart
|
| 61 |
+
|
| 62 |
+
```python
|
| 63 |
+
from PIL import Image
|
| 64 |
+
import librosa, torch
|
| 65 |
+
from transformers import AutoModel, AutoProcessor, WhisperFeatureExtractor
|
| 66 |
+
|
| 67 |
+
repo = "jinaai/jina-embeddings-v5-omni-nano"
|
| 68 |
+
model = AutoModel.from_pretrained(repo, trust_remote_code=True, default_task="retrieval").eval()
|
| 69 |
+
proc = AutoProcessor.from_pretrained(repo, trust_remote_code=True)
|
| 70 |
+
|
| 71 |
+
# model.embed(**inputs) returns L2-normalized last-token embeddings.
|
| 72 |
+
t_vec = model.embed(**proc(text="Query: Which planet is known as the Red Planet?", return_tensors="pt").to(model.device))
|
| 73 |
+
i_vec = model.embed(**proc(images=Image.open("photo.jpg"), text="<image>", return_tensors="pt").to(model.device))
|
| 74 |
+
v_vec = model.embed(**proc(videos="clip.mp4", text="<image>", return_tensors="pt").to(model.device))
|
| 75 |
+
|
| 76 |
+
# Audio has no string placeholder — build token ids from config.
|
| 77 |
+
audio, _ = librosa.load("speech.wav", sr=16000)
|
| 78 |
+
feat = WhisperFeatureExtractor(feature_size=128)(audio, sampling_rate=16000, return_tensors="pt")["input_features"]
|
| 79 |
+
cfg = model.config
|
| 80 |
+
n = feat.shape[-1] // 4
|
| 81 |
+
ids = torch.tensor([[cfg.audio_start_token_id, *[cfg.audio_token_id]*n, cfg.audio_end_token_id]])
|
| 82 |
+
a_vec = model.embed(
|
| 83 |
+
input_ids=ids.to(model.device),
|
| 84 |
+
attention_mask=torch.ones_like(ids).to(model.device),
|
| 85 |
+
input_features=feat.to(model.device, dtype=next(model.parameters()).dtype),
|
| 86 |
+
)
|
| 87 |
+
```
|
| 88 |
+
|
| 89 |
+
For retrieval, use `encode_query()` for query-side embeddings and `encode_document()` for document-side embeddings. A bare `encode(text)` call does not know which retrieval side you intended.
|
| 90 |
+
|
| 91 |
+
No `dtype`, `device`, `min_pixels`, or custom pooling code needed — sensible defaults live in the model config (bf16 weights, 256–1280 vision tokens).
|
| 92 |
+
|
| 93 |
+
<details>
|
| 94 |
+
<summary>Requirements</summary>
|
| 95 |
+
|
| 96 |
+
- `transformers>=4.57` (recommend >=5.1 for the small variants)
|
| 97 |
+
- `torch>=2.5`
|
| 98 |
+
|
| 99 |
+
Optional:
|
| 100 |
+
- `sentence-transformers` — one-call API for all 4 modalities
|
| 101 |
+
- `librosa` — audio decoding
|
| 102 |
+
- `av` — video decoding (`pip install av`)
|
| 103 |
+
- `vllm==0.20.1` — high-throughput serving; H100 deployments may also need DeepGEMM installed for vLLM FP8 kernels
|
| 104 |
+
|
| 105 |
+
</details>
|
| 106 |
+
|
| 107 |
+
### Selective Modality Loading
|
| 108 |
+
|
| 109 |
+
By default all components (vision + audio towers + text encoder) are loaded.
|
| 110 |
+
To save memory, pick a subset — the unused towers are skipped at load time:
|
| 111 |
+
|
| 112 |
+
```python
|
| 113 |
+
from transformers import AutoModel
|
| 114 |
+
|
| 115 |
+
AutoModel.from_pretrained("jinaai/jina-embeddings-v5-omni-nano", trust_remote_code=True, modality="omni") # all (default)
|
| 116 |
+
AutoModel.from_pretrained("jinaai/jina-embeddings-v5-omni-nano", trust_remote_code=True, modality="vision") # vision + text
|
| 117 |
+
AutoModel.from_pretrained("jinaai/jina-embeddings-v5-omni-nano", trust_remote_code=True, modality="audio") # audio + text
|
| 118 |
+
AutoModel.from_pretrained("jinaai/jina-embeddings-v5-omni-nano", trust_remote_code=True, modality="text") # text only
|
| 119 |
+
```
|
| 120 |
+
|
| 121 |
+
Same parameter works via `sentence-transformers`:
|
| 122 |
+
|
| 123 |
+
```python
|
| 124 |
+
SentenceTransformer("jinaai/jina-embeddings-v5-omni-nano", trust_remote_code=True, model_kwargs={"modality": "vision"})
|
| 125 |
+
```
|
| 126 |
+
|
| 127 |
+
### Via sentence-transformers
|
| 128 |
+
|
| 129 |
+
```python
|
| 130 |
+
from sentence_transformers import SentenceTransformer
|
| 131 |
+
|
| 132 |
+
# Base repo holds all 4 task adapters — pick one at load time.
|
| 133 |
+
model = SentenceTransformer(
|
| 134 |
+
"jinaai/jina-embeddings-v5-omni-nano",
|
| 135 |
+
trust_remote_code=True,
|
| 136 |
+
model_kwargs={"default_task": "retrieval"},
|
| 137 |
+
)
|
| 138 |
+
|
| 139 |
+
# URLs, local paths (with or without extension), PIL.Image, np.ndarray,
|
| 140 |
+
# torch.Tensor, bytes, and BytesIO are all accepted directly.
|
| 141 |
+
q_vec = model.encode_query("Which planet is known as the Red Planet?")
|
| 142 |
+
d_vec = model.encode_document("Mars is often referred to as the Red Planet due to its reddish appearance.")
|
| 143 |
+
i_vec = model.encode("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/car.jpg")
|
| 144 |
+
v_vec = model.encode("https://huggingface.co/datasets/raushan-testing-hf/videos-test/resolve/main/sample_demo_1.mp4") # needs `pip install av`
|
| 145 |
+
a_vec = model.encode("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac") # needs `pip install librosa soundfile`
|
| 146 |
+
|
| 147 |
+
# Fused multimodal — a tuple becomes ONE embedding in a single forward pass:
|
| 148 |
+
emb = model.encode(("Winter boots, waterproof leather upper",
|
| 149 |
+
"https://.../boot.jpg",
|
| 150 |
+
"https://.../boot.mp4"))
|
| 151 |
+
```
|
| 152 |
+
|
| 153 |
+
For non-retrieval tasks (classification / clustering / text-matching), reload
|
| 154 |
+
with the corresponding `default_task` — no `prompt_name` needed.
|
| 155 |
+
|
| 156 |
+
No `dtype`, `device`, `min_pixels`, or custom pooling code needed — sensible defaults live in the model config (bf16 weights, 256–1280 vision tokens).
|
| 157 |
+
|
| 158 |
+
<!-- VIDEO_INPUT_TYPES_DETAILS -->
|
| 159 |
+
<details><summary>Accepted video inputs</summary>
|
| 160 |
+
|
| 161 |
+
Path (`.mp4 .avi .mov .mkv .webm .flv .wmv`, or extensionless — content-sniffed), HTTP(S) URL, `bytes`/`io.BytesIO`, and in-memory `np.ndarray` / `torch.Tensor` of shape `(T, H, W, 3|4)` with dtype `uint8`. In-memory arrays are encoded to MP4 on the fly (needs `pip install imageio imageio-ffmpeg`).
|
| 162 |
+
|
| 163 |
+
```python
|
| 164 |
+
import numpy as np
|
| 165 |
+
# (T, H, W, 3) uint8 — e.g. from decord, imageio, or an rgb frame buffer
|
| 166 |
+
frames = np.zeros((16, 224, 224, 3), dtype=np.uint8)
|
| 167 |
+
v_vec = model.encode(frames)
|
| 168 |
+
```
|
| 169 |
+
|
| 170 |
+
</details>
|
| 171 |
+
|
| 172 |
+
### Via vLLM
|
| 173 |
+
|
| 174 |
+
The base repo holds all 4 task adapters. Pick **one task per vLLM instance** via `hf_overrides`:
|
| 175 |
+
|
| 176 |
+
```python
|
| 177 |
+
from vllm import LLM
|
| 178 |
+
llm = LLM(
|
| 179 |
+
model="jinaai/jina-embeddings-v5-omni-nano",
|
| 180 |
+
runner="pooling",
|
| 181 |
+
trust_remote_code=True,
|
| 182 |
+
hf_overrides={"task": "retrieval"}, # or: classification / clustering / text-matching
|
| 183 |
+
)
|
| 184 |
+
outs = llm.embed([{"prompt": "Which planet is known as the Red Planet?"}])
|
| 185 |
+
```
|
| 186 |
+
|
| 187 |
+
Or via CLI:
|
| 188 |
+
|
| 189 |
+
```bash
|
| 190 |
+
vllm serve jinaai/jina-embeddings-v5-omni-nano \
|
| 191 |
+
--trust-remote-code \
|
| 192 |
+
--hf-overrides '{"task": "retrieval"}'
|
| 193 |
+
```
|
| 194 |
+
|
| 195 |
+
Alternatively set `JINA_V5_TASK=retrieval` in the environment. Output is bit-exact
|
| 196 |
+
with the corresponding pre-merged `-retrieval` / `-classification` / `-clustering` /
|
| 197 |
+
`-text-matching` variant.
|
| 198 |
+
|
| 199 |
+
### Matryoshka (truncating embeddings)
|
| 200 |
+
|
| 201 |
+
All three backends support truncating the full embedding to a shorter dimension
|
| 202 |
+
with L2 re-normalization, so the result stays unit-norm:
|
| 203 |
+
|
| 204 |
+
```python
|
| 205 |
+
# transformers
|
| 206 |
+
vec = model.embed(truncate_dim=256, **proc(text="hello", return_tensors="pt"))
|
| 207 |
+
# or
|
| 208 |
+
vec = model.encode(["hello"], task="retrieval", truncate_dim=256)
|
| 209 |
+
|
| 210 |
+
# sentence-transformers
|
| 211 |
+
vec = model.encode("hello", truncate_dim=256)
|
| 212 |
+
|
| 213 |
+
# vLLM — ask the pooler for a smaller embedding
|
| 214 |
+
from vllm import PoolingParams
|
| 215 |
+
outs = llm.embed(prompts, pooling_params=PoolingParams(dimensions=256))
|
| 216 |
+
# or truncate + renormalize the full-dim output yourself:
|
| 217 |
+
import numpy as np
|
| 218 |
+
full = np.asarray(outs[0].outputs.embedding)
|
| 219 |
+
vec = full[:256] / np.linalg.norm(full[:256])
|
| 220 |
+
```
|
| 221 |
+
|
| 222 |
+
<!-- BATCHING_SECTION_START -->
|
| 223 |
+
### Batching
|
| 224 |
+
|
| 225 |
+
Pass a list to encode many inputs in one call.
|
| 226 |
+
|
| 227 |
+
```python
|
| 228 |
+
# sentence-transformers — any modality
|
| 229 |
+
t_vecs = model.encode(["query 1", "query 2"])
|
| 230 |
+
i_vecs = model.encode([Image.open("a.jpg"), Image.open("b.jpg")])
|
| 231 |
+
v_vecs = model.encode(["clip1.mp4", "clip2.mp4"])
|
| 232 |
+
a_vecs = model.encode(["speech1.wav", "speech2.wav"])
|
| 233 |
+
|
| 234 |
+
# raw transformers — text (native padded batch)
|
| 235 |
+
inputs = proc(text=["query 1", "query 2"], padding=True, truncation=True, return_tensors="pt").to(model.device)
|
| 236 |
+
vecs = model.embed(**inputs) # (2, dim)
|
| 237 |
+
|
| 238 |
+
# vLLM — list of request dicts, any modality
|
| 239 |
+
outs = llm.embed([
|
| 240 |
+
{"prompt": "query 1"},
|
| 241 |
+
{"prompt": "query 2"},
|
| 242 |
+
])
|
| 243 |
+
```
|
| 244 |
+
|
| 245 |
+
For `sentence-transformers`, images / video / audio are forwarded per-sample (one forward pass each). Text is truly batched. For large-scale multimodal throughput, prefer `vLLM`.
|
| 246 |
+
|
| 247 |
+
<!-- BATCHING_SECTION_END -->
|
| 248 |
+
|
| 249 |
+
### Compatibility
|
| 250 |
+
|
| 251 |
+
Embeddings produced by this model share a vector space with:
|
| 252 |
+
- [`jinaai/jina-embeddings-v5-text-nano`](https://huggingface.co/jinaai/jina-embeddings-v5-text-nano) — text-only
|
| 253 |
+
- `jinaai/jina-embeddings-v5-text-nano` (via matching adapter)
|
| 254 |
+
|
| 255 |
+
You can index text with the `v5-text-nano` model and query it with image,
|
| 256 |
+
video, or audio embeddings from `jina-embeddings-v5-omni-nano` — no reindexing.
|
| 257 |
+
|
| 258 |
+
### License
|
| 259 |
+
|
| 260 |
+
CC BY-NC 4.0. For commercial use, [contact us](mailto:sales@jina.ai).
|
adapters/classification/adapter_config.json
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"alpha_pattern": {},
|
| 3 |
+
"auto_mapping": null,
|
| 4 |
+
"base_model_name_or_path": "jinaai/jina-embeddings-v5-omni-nano",
|
| 5 |
+
"bias": "none",
|
| 6 |
+
"corda_config": null,
|
| 7 |
+
"eva_config": null,
|
| 8 |
+
"exclude_modules": null,
|
| 9 |
+
"fan_in_fan_out": false,
|
| 10 |
+
"inference_mode": true,
|
| 11 |
+
"init_lora_weights": "gaussian",
|
| 12 |
+
"layer_replication": null,
|
| 13 |
+
"layers_pattern": null,
|
| 14 |
+
"layers_to_transform": null,
|
| 15 |
+
"loftq_config": {},
|
| 16 |
+
"lora_alpha": 32,
|
| 17 |
+
"lora_bias": false,
|
| 18 |
+
"lora_dropout": 0.05,
|
| 19 |
+
"megatron_config": null,
|
| 20 |
+
"megatron_core": "megatron.core",
|
| 21 |
+
"modules_to_save": null,
|
| 22 |
+
"peft_type": "LORA",
|
| 23 |
+
"r": 32,
|
| 24 |
+
"rank_pattern": {},
|
| 25 |
+
"revision": null,
|
| 26 |
+
"target_modules": [
|
| 27 |
+
"o_proj",
|
| 28 |
+
"k_proj",
|
| 29 |
+
"q_proj",
|
| 30 |
+
"down_proj",
|
| 31 |
+
"gate_proj",
|
| 32 |
+
"v_proj",
|
| 33 |
+
"up_proj"
|
| 34 |
+
],
|
| 35 |
+
"task_type": "FEATURE_EXTRACTION",
|
| 36 |
+
"trainable_token_indices": null,
|
| 37 |
+
"use_dora": false,
|
| 38 |
+
"use_rslora": false
|
| 39 |
+
}
|
adapters/classification/adapter_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:13c8389381221af49bbe1d40231f50b28e354c901af57e6b1a1b3a6ec34f42b2
|
| 3 |
+
size 13589512
|
adapters/clustering/adapter_config.json
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"alpha_pattern": {},
|
| 3 |
+
"auto_mapping": null,
|
| 4 |
+
"base_model_name_or_path": "jinaai/jina-embeddings-v5-omni-nano",
|
| 5 |
+
"bias": "none",
|
| 6 |
+
"corda_config": null,
|
| 7 |
+
"eva_config": null,
|
| 8 |
+
"exclude_modules": null,
|
| 9 |
+
"fan_in_fan_out": false,
|
| 10 |
+
"inference_mode": true,
|
| 11 |
+
"init_lora_weights": "gaussian",
|
| 12 |
+
"layer_replication": null,
|
| 13 |
+
"layers_pattern": null,
|
| 14 |
+
"layers_to_transform": null,
|
| 15 |
+
"loftq_config": {},
|
| 16 |
+
"lora_alpha": 32,
|
| 17 |
+
"lora_bias": false,
|
| 18 |
+
"lora_dropout": 0.1,
|
| 19 |
+
"megatron_config": null,
|
| 20 |
+
"megatron_core": "megatron.core",
|
| 21 |
+
"modules_to_save": null,
|
| 22 |
+
"peft_type": "LORA",
|
| 23 |
+
"r": 32,
|
| 24 |
+
"rank_pattern": {},
|
| 25 |
+
"revision": null,
|
| 26 |
+
"target_modules": [
|
| 27 |
+
"q_proj",
|
| 28 |
+
"down_proj",
|
| 29 |
+
"gate_proj",
|
| 30 |
+
"v_proj",
|
| 31 |
+
"o_proj",
|
| 32 |
+
"k_proj",
|
| 33 |
+
"up_proj"
|
| 34 |
+
],
|
| 35 |
+
"task_type": "FEATURE_EXTRACTION",
|
| 36 |
+
"trainable_token_indices": null,
|
| 37 |
+
"use_dora": false,
|
| 38 |
+
"use_rslora": false
|
| 39 |
+
}
|
adapters/clustering/adapter_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:030822246d646a74a9886410eddcc80c663384bcaeacd31a869a523f35268c5f
|
| 3 |
+
size 13589512
|
adapters/retrieval/adapter_config.json
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"alpha_pattern": {},
|
| 3 |
+
"auto_mapping": null,
|
| 4 |
+
"base_model_name_or_path": "jinaai/jina-embeddings-v5-omni-nano",
|
| 5 |
+
"bias": "none",
|
| 6 |
+
"corda_config": null,
|
| 7 |
+
"eva_config": null,
|
| 8 |
+
"exclude_modules": null,
|
| 9 |
+
"fan_in_fan_out": false,
|
| 10 |
+
"inference_mode": true,
|
| 11 |
+
"init_lora_weights": "gaussian",
|
| 12 |
+
"layer_replication": null,
|
| 13 |
+
"layers_pattern": null,
|
| 14 |
+
"layers_to_transform": null,
|
| 15 |
+
"loftq_config": {},
|
| 16 |
+
"lora_alpha": 32,
|
| 17 |
+
"lora_bias": false,
|
| 18 |
+
"lora_dropout": 0.1,
|
| 19 |
+
"megatron_config": null,
|
| 20 |
+
"megatron_core": "megatron.core",
|
| 21 |
+
"modules_to_save": null,
|
| 22 |
+
"peft_type": "LORA",
|
| 23 |
+
"r": 32,
|
| 24 |
+
"rank_pattern": {},
|
| 25 |
+
"revision": null,
|
| 26 |
+
"target_modules": [
|
| 27 |
+
"gate_proj",
|
| 28 |
+
"v_proj",
|
| 29 |
+
"q_proj",
|
| 30 |
+
"down_proj",
|
| 31 |
+
"o_proj",
|
| 32 |
+
"k_proj",
|
| 33 |
+
"up_proj"
|
| 34 |
+
],
|
| 35 |
+
"task_type": "FEATURE_EXTRACTION",
|
| 36 |
+
"trainable_token_indices": null,
|
| 37 |
+
"use_dora": false,
|
| 38 |
+
"use_rslora": false
|
| 39 |
+
}
|
adapters/retrieval/adapter_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9c2b4bd34101afd04833c5626958724e7587c292ffc6564788cfa10af89a2157
|
| 3 |
+
size 13589512
|
adapters/text-matching/adapter_config.json
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"alpha_pattern": {},
|
| 3 |
+
"auto_mapping": null,
|
| 4 |
+
"base_model_name_or_path": "jinaai/jina-embeddings-v5-omni-nano",
|
| 5 |
+
"bias": "none",
|
| 6 |
+
"corda_config": null,
|
| 7 |
+
"eva_config": null,
|
| 8 |
+
"exclude_modules": null,
|
| 9 |
+
"fan_in_fan_out": false,
|
| 10 |
+
"inference_mode": true,
|
| 11 |
+
"init_lora_weights": "gaussian",
|
| 12 |
+
"layer_replication": null,
|
| 13 |
+
"layers_pattern": null,
|
| 14 |
+
"layers_to_transform": null,
|
| 15 |
+
"loftq_config": {},
|
| 16 |
+
"lora_alpha": 32,
|
| 17 |
+
"lora_bias": false,
|
| 18 |
+
"lora_dropout": 0.1,
|
| 19 |
+
"megatron_config": null,
|
| 20 |
+
"megatron_core": "megatron.core",
|
| 21 |
+
"modules_to_save": null,
|
| 22 |
+
"peft_type": "LORA",
|
| 23 |
+
"r": 32,
|
| 24 |
+
"rank_pattern": {},
|
| 25 |
+
"revision": null,
|
| 26 |
+
"target_modules": [
|
| 27 |
+
"k_proj",
|
| 28 |
+
"v_proj",
|
| 29 |
+
"o_proj",
|
| 30 |
+
"down_proj",
|
| 31 |
+
"q_proj",
|
| 32 |
+
"gate_proj",
|
| 33 |
+
"up_proj"
|
| 34 |
+
],
|
| 35 |
+
"task_type": "FEATURE_EXTRACTION",
|
| 36 |
+
"trainable_token_indices": null,
|
| 37 |
+
"use_dora": false,
|
| 38 |
+
"use_rslora": false
|
| 39 |
+
}
|
adapters/text-matching/adapter_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:24bb801dbc7e565e9a64e12ef0049fc2631c381f50a215a83cf90fe0ccba2e0e
|
| 3 |
+
size 13589512
|
architecture.png
ADDED
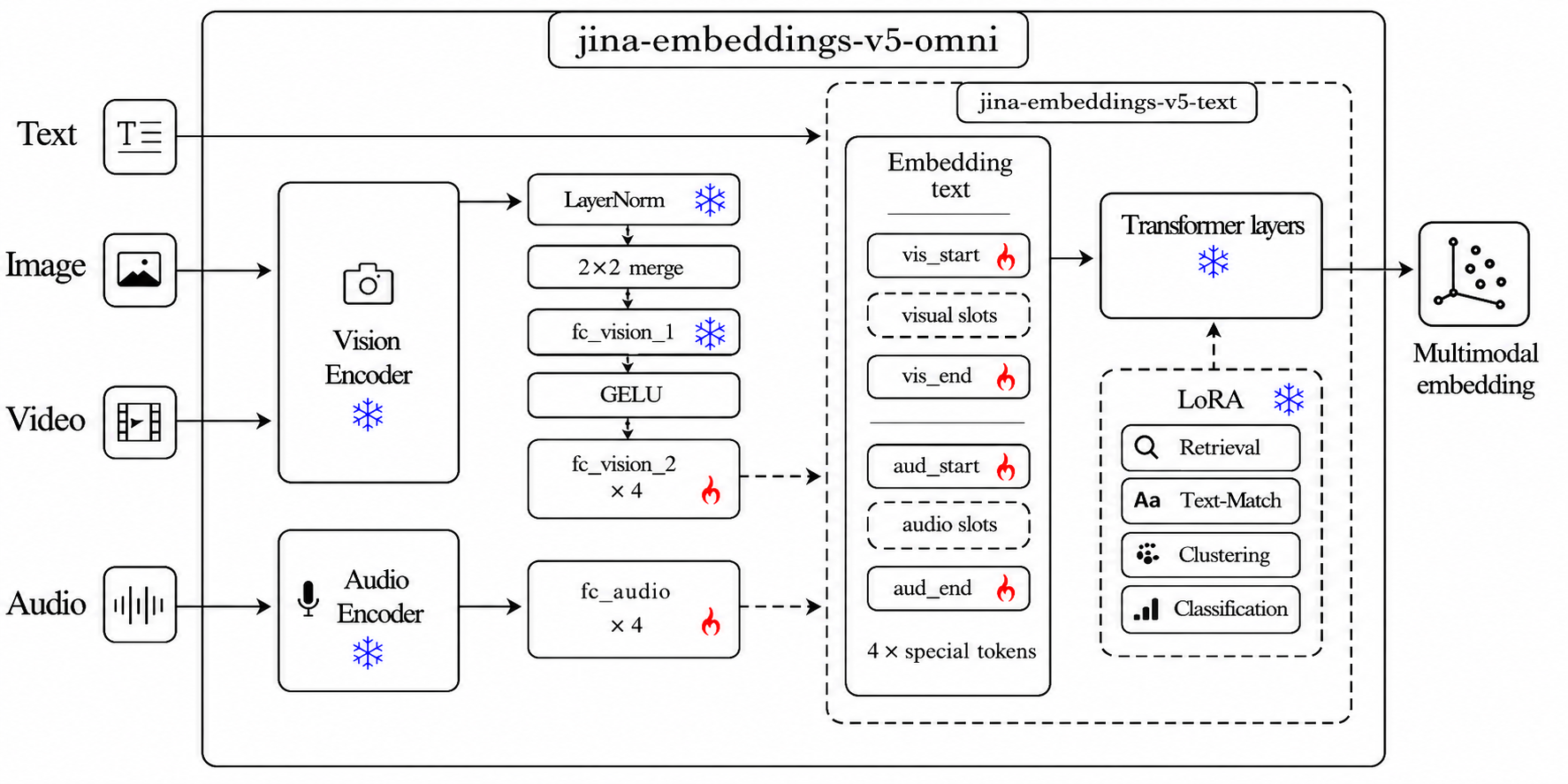
|
Git LFS Details
|
chat_template.jinja
ADDED
|
@@ -0,0 +1,154 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{%- set image_count = namespace(value=0) %}
|
| 2 |
+
{%- set video_count = namespace(value=0) %}
|
| 3 |
+
{%- macro render_content(content, do_vision_count, is_system_content=false) %}
|
| 4 |
+
{%- if content is string %}
|
| 5 |
+
{{- content }}
|
| 6 |
+
{%- elif content is iterable and content is not mapping %}
|
| 7 |
+
{%- for item in content %}
|
| 8 |
+
{%- if 'image' in item or 'image_url' in item or item.type == 'image' %}
|
| 9 |
+
{%- if is_system_content %}
|
| 10 |
+
{{- raise_exception('System message cannot contain images.') }}
|
| 11 |
+
{%- endif %}
|
| 12 |
+
{%- if do_vision_count %}
|
| 13 |
+
{%- set image_count.value = image_count.value + 1 %}
|
| 14 |
+
{%- endif %}
|
| 15 |
+
{%- if add_vision_id %}
|
| 16 |
+
{{- 'Picture ' ~ image_count.value ~ ': ' }}
|
| 17 |
+
{%- endif %}
|
| 18 |
+
{{- '<|vision_start|><|image_pad|><|vision_end|>' }}
|
| 19 |
+
{%- elif 'video' in item or item.type == 'video' %}
|
| 20 |
+
{%- if is_system_content %}
|
| 21 |
+
{{- raise_exception('System message cannot contain videos.') }}
|
| 22 |
+
{%- endif %}
|
| 23 |
+
{%- if do_vision_count %}
|
| 24 |
+
{%- set video_count.value = video_count.value + 1 %}
|
| 25 |
+
{%- endif %}
|
| 26 |
+
{%- if add_vision_id %}
|
| 27 |
+
{{- 'Video ' ~ video_count.value ~ ': ' }}
|
| 28 |
+
{%- endif %}
|
| 29 |
+
{{- '<|vision_start|><|video_pad|><|vision_end|>' }}
|
| 30 |
+
{%- elif 'text' in item %}
|
| 31 |
+
{{- item.text }}
|
| 32 |
+
{%- else %}
|
| 33 |
+
{{- raise_exception('Unexpected item type in content.') }}
|
| 34 |
+
{%- endif %}
|
| 35 |
+
{%- endfor %}
|
| 36 |
+
{%- elif content is none or content is undefined %}
|
| 37 |
+
{{- '' }}
|
| 38 |
+
{%- else %}
|
| 39 |
+
{{- raise_exception('Unexpected content type.') }}
|
| 40 |
+
{%- endif %}
|
| 41 |
+
{%- endmacro %}
|
| 42 |
+
{%- if not messages %}
|
| 43 |
+
{{- raise_exception('No messages provided.') }}
|
| 44 |
+
{%- endif %}
|
| 45 |
+
{%- if tools and tools is iterable and tools is not mapping %}
|
| 46 |
+
{{- '<|im_start|>system\n' }}
|
| 47 |
+
{{- "# Tools\n\nYou have access to the following functions:\n\n<tools>" }}
|
| 48 |
+
{%- for tool in tools %}
|
| 49 |
+
{{- "\n" }}
|
| 50 |
+
{{- tool | tojson }}
|
| 51 |
+
{%- endfor %}
|
| 52 |
+
{{- "\n</tools>" }}
|
| 53 |
+
{{- '\n\nIf you choose to call a function ONLY reply in the following format with NO suffix:\n\n<tool_call>\n<function=example_function_name>\n<parameter=example_parameter_1>\nvalue_1\n</parameter>\n<parameter=example_parameter_2>\nThis is the value for the second parameter\nthat can span\nmultiple lines\n</parameter>\n</function>\n</tool_call>\n\n<IMPORTANT>\nReminder:\n- Function calls MUST follow the specified format: an inner <function=...></function> block must be nested within <tool_call></tool_call> XML tags\n- Required parameters MUST be specified\n- You may provide optional reasoning for your function call in natural language BEFORE the function call, but NOT after\n- If there is no function call available, answer the question like normal with your current knowledge and do not tell the user about function calls\n</IMPORTANT>' }}
|
| 54 |
+
{%- if messages[0].role == 'system' %}
|
| 55 |
+
{%- set content = render_content(messages[0].content, false, true)|trim %}
|
| 56 |
+
{%- if content %}
|
| 57 |
+
{{- '\n\n' + content }}
|
| 58 |
+
{%- endif %}
|
| 59 |
+
{%- endif %}
|
| 60 |
+
{{- '<|im_end|>\n' }}
|
| 61 |
+
{%- else %}
|
| 62 |
+
{%- if messages[0].role == 'system' %}
|
| 63 |
+
{%- set content = render_content(messages[0].content, false, true)|trim %}
|
| 64 |
+
{{- '<|im_start|>system\n' + content + '<|im_end|>\n' }}
|
| 65 |
+
{%- endif %}
|
| 66 |
+
{%- endif %}
|
| 67 |
+
{%- set ns = namespace(multi_step_tool=true, last_query_index=messages|length - 1) %}
|
| 68 |
+
{%- for message in messages[::-1] %}
|
| 69 |
+
{%- set index = (messages|length - 1) - loop.index0 %}
|
| 70 |
+
{%- if ns.multi_step_tool and message.role == "user" %}
|
| 71 |
+
{%- set content = render_content(message.content, false)|trim %}
|
| 72 |
+
{%- if not(content.startswith('<tool_response>') and content.endswith('</tool_response>')) %}
|
| 73 |
+
{%- set ns.multi_step_tool = false %}
|
| 74 |
+
{%- set ns.last_query_index = index %}
|
| 75 |
+
{%- endif %}
|
| 76 |
+
{%- endif %}
|
| 77 |
+
{%- endfor %}
|
| 78 |
+
{%- if ns.multi_step_tool %}
|
| 79 |
+
{{- raise_exception('No user query found in messages.') }}
|
| 80 |
+
{%- endif %}
|
| 81 |
+
{%- for message in messages %}
|
| 82 |
+
{%- set content = render_content(message.content, true)|trim %}
|
| 83 |
+
{%- if message.role == "system" %}
|
| 84 |
+
{%- if not loop.first %}
|
| 85 |
+
{{- raise_exception('System message must be at the beginning.') }}
|
| 86 |
+
{%- endif %}
|
| 87 |
+
{%- elif message.role == "user" %}
|
| 88 |
+
{{- '<|im_start|>' + message.role + '\n' + content + '<|im_end|>' + '\n' }}
|
| 89 |
+
{%- elif message.role == "assistant" %}
|
| 90 |
+
{%- set reasoning_content = '' %}
|
| 91 |
+
{%- if message.reasoning_content is string %}
|
| 92 |
+
{%- set reasoning_content = message.reasoning_content %}
|
| 93 |
+
{%- else %}
|
| 94 |
+
{%- if '</think>' in content %}
|
| 95 |
+
{%- set reasoning_content = content.split('</think>')[0].rstrip('\n').split('<think>')[-1].lstrip('\n') %}
|
| 96 |
+
{%- set content = content.split('</think>')[-1].lstrip('\n') %}
|
| 97 |
+
{%- endif %}
|
| 98 |
+
{%- endif %}
|
| 99 |
+
{%- set reasoning_content = reasoning_content|trim %}
|
| 100 |
+
{%- if loop.index0 > ns.last_query_index %}
|
| 101 |
+
{{- '<|im_start|>' + message.role + '\n<think>\n' + reasoning_content + '\n</think>\n\n' + content }}
|
| 102 |
+
{%- else %}
|
| 103 |
+
{{- '<|im_start|>' + message.role + '\n' + content }}
|
| 104 |
+
{%- endif %}
|
| 105 |
+
{%- if message.tool_calls and message.tool_calls is iterable and message.tool_calls is not mapping %}
|
| 106 |
+
{%- for tool_call in message.tool_calls %}
|
| 107 |
+
{%- if tool_call.function is defined %}
|
| 108 |
+
{%- set tool_call = tool_call.function %}
|
| 109 |
+
{%- endif %}
|
| 110 |
+
{%- if loop.first %}
|
| 111 |
+
{%- if content|trim %}
|
| 112 |
+
{{- '\n\n<tool_call>\n<function=' + tool_call.name + '>\n' }}
|
| 113 |
+
{%- else %}
|
| 114 |
+
{{- '<tool_call>\n<function=' + tool_call.name + '>\n' }}
|
| 115 |
+
{%- endif %}
|
| 116 |
+
{%- else %}
|
| 117 |
+
{{- '\n<tool_call>\n<function=' + tool_call.name + '>\n' }}
|
| 118 |
+
{%- endif %}
|
| 119 |
+
{%- if tool_call.arguments is defined %}
|
| 120 |
+
{%- for args_name, args_value in tool_call.arguments|items %}
|
| 121 |
+
{{- '<parameter=' + args_name + '>\n' }}
|
| 122 |
+
{%- set args_value = args_value | tojson | safe if args_value is mapping or (args_value is sequence and args_value is not string) else args_value | string %}
|
| 123 |
+
{{- args_value }}
|
| 124 |
+
{{- '\n</parameter>\n' }}
|
| 125 |
+
{%- endfor %}
|
| 126 |
+
{%- endif %}
|
| 127 |
+
{{- '</function>\n</tool_call>' }}
|
| 128 |
+
{%- endfor %}
|
| 129 |
+
{%- endif %}
|
| 130 |
+
{{- '<|im_end|>\n' }}
|
| 131 |
+
{%- elif message.role == "tool" %}
|
| 132 |
+
{%- if loop.previtem and loop.previtem.role != "tool" %}
|
| 133 |
+
{{- '<|im_start|>user' }}
|
| 134 |
+
{%- endif %}
|
| 135 |
+
{{- '\n<tool_response>\n' }}
|
| 136 |
+
{{- content }}
|
| 137 |
+
{{- '\n</tool_response>' }}
|
| 138 |
+
{%- if not loop.last and loop.nextitem.role != "tool" %}
|
| 139 |
+
{{- '<|im_end|>\n' }}
|
| 140 |
+
{%- elif loop.last %}
|
| 141 |
+
{{- '<|im_end|>\n' }}
|
| 142 |
+
{%- endif %}
|
| 143 |
+
{%- else %}
|
| 144 |
+
{{- raise_exception('Unexpected message role.') }}
|
| 145 |
+
{%- endif %}
|
| 146 |
+
{%- endfor %}
|
| 147 |
+
{%- if add_generation_prompt %}
|
| 148 |
+
{{- '<|im_start|>assistant\n' }}
|
| 149 |
+
{%- if enable_thinking is defined and enable_thinking is true %}
|
| 150 |
+
{{- '<think>\n' }}
|
| 151 |
+
{%- else %}
|
| 152 |
+
{{- '<think>\n\n</think>\n\n' }}
|
| 153 |
+
{%- endif %}
|
| 154 |
+
{%- endif %}
|
config.json
ADDED
|
@@ -0,0 +1,101 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"JinaEmbeddingsV5OmniModel"
|
| 4 |
+
],
|
| 5 |
+
"auto_map": {
|
| 6 |
+
"AutoConfig": "modeling_jina_embeddings_v5_omni.JinaEmbeddingsV5OmniConfig",
|
| 7 |
+
"AutoModel": "modeling_jina_embeddings_v5_omni.JinaEmbeddingsV5OmniModel"
|
| 8 |
+
},
|
| 9 |
+
"model_type": "jina_embeddings_v5_omni",
|
| 10 |
+
"task_names": [
|
| 11 |
+
"retrieval",
|
| 12 |
+
"text-matching",
|
| 13 |
+
"clustering",
|
| 14 |
+
"classification"
|
| 15 |
+
],
|
| 16 |
+
"special_token_ids": [
|
| 17 |
+
128256,
|
| 18 |
+
128257,
|
| 19 |
+
128258,
|
| 20 |
+
128259
|
| 21 |
+
],
|
| 22 |
+
"vision_config": {
|
| 23 |
+
"deepstack_visual_indexes": [],
|
| 24 |
+
"depth": 12,
|
| 25 |
+
"dtype": "bfloat16",
|
| 26 |
+
"hidden_act": "gelu_pytorch_tanh",
|
| 27 |
+
"hidden_size": 768,
|
| 28 |
+
"in_channels": 3,
|
| 29 |
+
"initializer_range": 0.02,
|
| 30 |
+
"intermediate_size": 3072,
|
| 31 |
+
"model_type": "",
|
| 32 |
+
"num_heads": 12,
|
| 33 |
+
"num_position_embeddings": 2304,
|
| 34 |
+
"out_hidden_size": 1024,
|
| 35 |
+
"patch_size": 16,
|
| 36 |
+
"spatial_merge_size": 2,
|
| 37 |
+
"temporal_patch_size": 2
|
| 38 |
+
},
|
| 39 |
+
"text_config": {
|
| 40 |
+
"attention_bias": false,
|
| 41 |
+
"attention_dropout": 0.0,
|
| 42 |
+
"bos_token_id": 1,
|
| 43 |
+
"eos_token_id": 2,
|
| 44 |
+
"head_dim": 64,
|
| 45 |
+
"hidden_act": "silu",
|
| 46 |
+
"hidden_size": 768,
|
| 47 |
+
"initializer_range": 0.02,
|
| 48 |
+
"intermediate_size": 3072,
|
| 49 |
+
"is_causal": false,
|
| 50 |
+
"max_position_embeddings": 8192,
|
| 51 |
+
"mlp_bias": false,
|
| 52 |
+
"model_type": "",
|
| 53 |
+
"num_attention_heads": 12,
|
| 54 |
+
"num_hidden_layers": 12,
|
| 55 |
+
"num_key_value_heads": 12,
|
| 56 |
+
"pad_token_id": null,
|
| 57 |
+
"pretraining_tp": 1,
|
| 58 |
+
"rms_norm_eps": 1e-05,
|
| 59 |
+
"rope_parameters": {
|
| 60 |
+
"rope_theta": 1000000.0,
|
| 61 |
+
"rope_type": "default"
|
| 62 |
+
},
|
| 63 |
+
"tie_word_embeddings": false,
|
| 64 |
+
"vocab_size": 128260
|
| 65 |
+
},
|
| 66 |
+
"audio_config": {
|
| 67 |
+
"activation_dropout": 0.0,
|
| 68 |
+
"activation_function": "gelu",
|
| 69 |
+
"attention_dropout": 0.0,
|
| 70 |
+
"d_model": 1280,
|
| 71 |
+
"dropout": 0.0,
|
| 72 |
+
"dtype": "float32",
|
| 73 |
+
"encoder_attention_heads": 20,
|
| 74 |
+
"encoder_ffn_dim": 5120,
|
| 75 |
+
"encoder_layers": 32,
|
| 76 |
+
"initializer_range": 0.02,
|
| 77 |
+
"max_source_positions": 1500,
|
| 78 |
+
"num_mel_bins": 128,
|
| 79 |
+
"scale_embedding": false,
|
| 80 |
+
"n_window": 100,
|
| 81 |
+
"output_dim": 3584
|
| 82 |
+
},
|
| 83 |
+
"image_token_index": 128259,
|
| 84 |
+
"audio_token_id": 128256,
|
| 85 |
+
"audio_start_token_id": 128257,
|
| 86 |
+
"audio_end_token_id": 128258,
|
| 87 |
+
"projector_hidden_act": "gelu",
|
| 88 |
+
"tie_word_embeddings": false,
|
| 89 |
+
"dtype": "bfloat16",
|
| 90 |
+
"transformers_version": "5.4.0",
|
| 91 |
+
"torch_dtype": "bfloat16",
|
| 92 |
+
"is_matryoshka": true,
|
| 93 |
+
"matryoshka_dimensions": [
|
| 94 |
+
32,
|
| 95 |
+
64,
|
| 96 |
+
128,
|
| 97 |
+
256,
|
| 98 |
+
512,
|
| 99 |
+
768
|
| 100 |
+
]
|
| 101 |
+
}
|
config_sentence_transformers.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"prompts": {
|
| 3 |
+
"query": "Query: ",
|
| 4 |
+
"document": "Document: "
|
| 5 |
+
},
|
| 6 |
+
"default_prompt_name": null,
|
| 7 |
+
"similarity_fn_name": "cosine"
|
| 8 |
+
}
|
custom_st.py
ADDED
|
@@ -0,0 +1,990 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Sentence-transformers integration for jina-embeddings-v5-omni-nano (base + LoRA).
|
| 2 |
+
|
| 3 |
+
Supports text, image, video, and audio with per-task adapter routing:
|
| 4 |
+
|
| 5 |
+
from sentence_transformers import SentenceTransformer
|
| 6 |
+
model = SentenceTransformer(
|
| 7 |
+
"jinaai/jina-embeddings-v5-omni-nano",
|
| 8 |
+
trust_remote_code=True,
|
| 9 |
+
model_kwargs={"default_task": "retrieval"},
|
| 10 |
+
)
|
| 11 |
+
q = model.encode("What is ML?", prompt_name="query")
|
| 12 |
+
d = model.encode("ML is ...", prompt_name="document")
|
| 13 |
+
img = model.encode(Image.open("photo.jpg"))
|
| 14 |
+
vid = model.encode("clip.mp4")
|
| 15 |
+
aud = model.encode("speech.wav")
|
| 16 |
+
"""
|
| 17 |
+
|
| 18 |
+
import json
|
| 19 |
+
import os
|
| 20 |
+
from typing import Any, Dict, List, Optional, Union
|
| 21 |
+
|
| 22 |
+
import torch
|
| 23 |
+
import torch.nn.functional as F
|
| 24 |
+
from torch import nn
|
| 25 |
+
from transformers import AutoConfig, AutoModel, AutoTokenizer
|
| 26 |
+
|
| 27 |
+
MAX_SEQ_LENGTH = 8192
|
| 28 |
+
IMAGE_PROMPT = "<image>"
|
| 29 |
+
VIDEO_PROMPT = "<image>"
|
| 30 |
+
AUDIO_EXTENSIONS = {".wav", ".mp3", ".flac", ".ogg", ".m4a", ".opus", ".webm"}
|
| 31 |
+
VIDEO_EXTENSIONS = {".mp4", ".avi", ".mov", ".mkv", ".webm", ".flv", ".wmv"}
|
| 32 |
+
PDF_EXTENSIONS = {".pdf"}
|
| 33 |
+
SVG_EXTENSIONS = {".svg"}
|
| 34 |
+
PDF_DPI = 150
|
| 35 |
+
TASK_NAMES = ["retrieval", "text-matching", "clustering", "classification"]
|
| 36 |
+
EVAL_IMAGE_MIN_PIXELS = 262144
|
| 37 |
+
EVAL_IMAGE_MAX_PIXELS = 1310720
|
| 38 |
+
EVAL_VIDEO_MAX_PIXELS = 12845056
|
| 39 |
+
EVAL_VIDEO_NUM_FRAMES = 32
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def _pil_image():
|
| 43 |
+
"""Return the PIL.Image module, with a clean ImportError if pillow is not
|
| 44 |
+
installed. Wrapped in `try` so transformers' AST-based `check_imports`
|
| 45 |
+
does not list PIL as a top-level required dependency: text-only and
|
| 46 |
+
audio-only users should not need pillow installed.
|
| 47 |
+
"""
|
| 48 |
+
try:
|
| 49 |
+
from PIL import Image as _PILImage
|
| 50 |
+
except ImportError as e:
|
| 51 |
+
raise ImportError(
|
| 52 |
+
"Encoding images or rasterising PDFs needs `pip install pillow`."
|
| 53 |
+
) from e
|
| 54 |
+
return _PILImage
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def _is_image(x) -> bool:
|
| 58 |
+
try:
|
| 59 |
+
from PIL import Image as PILImage
|
| 60 |
+
return isinstance(x, PILImage.Image)
|
| 61 |
+
except ImportError:
|
| 62 |
+
return False
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
def _is_video_path(x) -> bool:
|
| 66 |
+
if not isinstance(x, str):
|
| 67 |
+
return False
|
| 68 |
+
return any(x.lower().endswith(ext) for ext in VIDEO_EXTENSIONS)
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
def _is_audio_path(x) -> bool:
|
| 72 |
+
if not isinstance(x, str):
|
| 73 |
+
return False
|
| 74 |
+
return any(x.lower().endswith(ext) for ext in AUDIO_EXTENSIONS)
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def _is_pdf_path(x) -> bool:
|
| 78 |
+
if not isinstance(x, str):
|
| 79 |
+
return False
|
| 80 |
+
return any(x.lower().endswith(ext) for ext in PDF_EXTENSIONS)
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def _is_svg_path(x) -> bool:
|
| 84 |
+
if not isinstance(x, str):
|
| 85 |
+
return False
|
| 86 |
+
return any(x.lower().split("?", 1)[0].endswith(ext) for ext in SVG_EXTENSIONS)
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
def _is_audio_array(x) -> bool:
|
| 90 |
+
try:
|
| 91 |
+
import numpy as np
|
| 92 |
+
except ImportError:
|
| 93 |
+
return False
|
| 94 |
+
return isinstance(x, np.ndarray) and x.ndim == 1 and np.issubdtype(x.dtype, np.floating)
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
class _AudioWrapper:
|
| 98 |
+
def __init__(self, array, sampling_rate: int = 16000):
|
| 99 |
+
self.array = array
|
| 100 |
+
self.sampling_rate = sampling_rate
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
def _download_if_url(x):
|
| 104 |
+
"""If x is an http(s) URL, download to a hashed local cache and return the
|
| 105 |
+
local path. Otherwise return x unchanged.
|
| 106 |
+
"""
|
| 107 |
+
if not isinstance(x, str):
|
| 108 |
+
return x
|
| 109 |
+
if not (x.startswith("http://") or x.startswith("https://")):
|
| 110 |
+
return x
|
| 111 |
+
import hashlib, os, tempfile, urllib.request
|
| 112 |
+
from urllib.parse import urlparse
|
| 113 |
+
cache = os.path.join(tempfile.gettempdir(), "jina_omni_media_cache")
|
| 114 |
+
os.makedirs(cache, exist_ok=True)
|
| 115 |
+
h = hashlib.sha256(x.encode("utf-8")).hexdigest()[:16]
|
| 116 |
+
url_path = urlparse(x).path
|
| 117 |
+
_, ext = os.path.splitext(url_path)
|
| 118 |
+
local = os.path.join(cache, f"{h}{ext}" if ext else h)
|
| 119 |
+
if not os.path.isfile(local) or os.path.getsize(local) == 0:
|
| 120 |
+
urllib.request.urlretrieve(x, local)
|
| 121 |
+
return local
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
def _looks_like_svg(data):
|
| 125 |
+
if not data:
|
| 126 |
+
return False
|
| 127 |
+
head = data[:4096].lstrip().lower()
|
| 128 |
+
return b"<svg" in head
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
def _svg_to_image(svg):
|
| 132 |
+
try:
|
| 133 |
+
import cairosvg
|
| 134 |
+
except ImportError as e:
|
| 135 |
+
raise ImportError("Encoding SVG images needs `pip install cairosvg pillow`.") from e
|
| 136 |
+
import io
|
| 137 |
+
png = cairosvg.svg2png(bytestring=svg if isinstance(svg, (bytes, bytearray)) else None,
|
| 138 |
+
url=svg if isinstance(svg, str) else None)
|
| 139 |
+
_PILImage = _pil_image()
|
| 140 |
+
return _PILImage.open(io.BytesIO(png)).convert("RGB")
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
def _sniff_media_type_bytes(head):
|
| 144 |
+
"""Return 'image'/'svg'/'video'/'audio'/'pdf'/None from content headers."""
|
| 145 |
+
if _looks_like_svg(head):
|
| 146 |
+
return "svg"
|
| 147 |
+
if not head or len(head) < 8:
|
| 148 |
+
return None
|
| 149 |
+
if head[:3] == b"\xff\xd8\xff": return "image"
|
| 150 |
+
if head[:8] == b"\x89PNG\r\n\x1a\n": return "image"
|
| 151 |
+
if head[:6] in (b"GIF87a", b"GIF89a"): return "image"
|
| 152 |
+
if head[:4] == b"RIFF" and head[8:12] == b"WEBP": return "image"
|
| 153 |
+
if head[:2] == b"BM": return "image"
|
| 154 |
+
if head[:4] in (b"II*\x00", b"MM\x00*"): return "image"
|
| 155 |
+
if head[4:12] in (b"ftypavif", b"ftypavis"): return "image"
|
| 156 |
+
if head[4:12] in (b"ftypheic", b"ftypheix", b"ftypmif1", b"ftypmsf1"):
|
| 157 |
+
return "image"
|
| 158 |
+
if head[:3] == b"ID3": return "audio"
|
| 159 |
+
if head[:2] in (b"\xff\xfb", b"\xff\xf3", b"\xff\xf2"): return "audio"
|
| 160 |
+
if head[:4] == b"fLaC": return "audio"
|
| 161 |
+
if head[:4] == b"OggS": return "audio"
|
| 162 |
+
if head[:4] == b"RIFF" and head[8:12] == b"WAVE": return "audio"
|
| 163 |
+
if head[4:12] in (b"M4A ", b"M4B ", b"M4P "): return "audio"
|
| 164 |
+
if head[:4] == b"\x1a\x45\xdf\xa3": return "video"
|
| 165 |
+
if head[4:8] == b"ftyp": return "video"
|
| 166 |
+
if head[:4] == b"RIFF" and head[8:12] == b"AVI ": return "video"
|
| 167 |
+
if head[:3] == b"FLV": return "video"
|
| 168 |
+
if head[:4] == b"0&\xb2u": return "video"
|
| 169 |
+
if head[:5] == b"%PDF-": return "pdf"
|
| 170 |
+
return None
|
| 171 |
+
|
| 172 |
+
|
| 173 |
+
def _sniff_media_type(path):
|
| 174 |
+
try:
|
| 175 |
+
with open(path, "rb") as f:
|
| 176 |
+
data = f.read(4096)
|
| 177 |
+
kind = _sniff_media_type_bytes(data)
|
| 178 |
+
if kind is None and _is_svg_path(path):
|
| 179 |
+
return "svg"
|
| 180 |
+
return kind
|
| 181 |
+
except OSError:
|
| 182 |
+
return None
|
| 183 |
+
|
| 184 |
+
|
| 185 |
+
def _resolve_input(x):
|
| 186 |
+
"""Normalize any input to (kind, value). Accepts:
|
| 187 |
+
- PIL.Image -> image
|
| 188 |
+
- np.ndarray HxWx3 uint8 -> image (via PIL.fromarray)
|
| 189 |
+
- np.ndarray TxHxWx3 uint8 -> video (saved to /tmp via imageio)
|
| 190 |
+
- np.ndarray 1-D float -> audio
|
| 191 |
+
- np.ndarray 2-D float (C,N) or (N,C) -> audio (mono mixdown)
|
| 192 |
+
- torch.Tensor -> converted to numpy, recurse
|
| 193 |
+
- bytes / io.IOBase -> sniff + route
|
| 194 |
+
- str URL -> downloaded + routed
|
| 195 |
+
- str path -> content-sniffed + routed
|
| 196 |
+
- str -> text
|
| 197 |
+
"""
|
| 198 |
+
import os as _os
|
| 199 |
+
import io
|
| 200 |
+
|
| 201 |
+
if _is_image(x):
|
| 202 |
+
return ("image", x)
|
| 203 |
+
if _is_audio_array(x):
|
| 204 |
+
return ("audio", x)
|
| 205 |
+
|
| 206 |
+
try:
|
| 207 |
+
import numpy as _np
|
| 208 |
+
except ImportError:
|
| 209 |
+
_np = None
|
| 210 |
+
|
| 211 |
+
if _np is not None and isinstance(x, _np.ndarray):
|
| 212 |
+
# Image (H,W,3|4) uint8
|
| 213 |
+
if x.ndim == 3 and x.shape[-1] in (3, 4) and x.dtype == _np.uint8:
|
| 214 |
+
_PILImage = _pil_image()
|
| 215 |
+
mode = "RGBA" if x.shape[-1] == 4 else "RGB"
|
| 216 |
+
return ("image", _PILImage.fromarray(x, mode).convert("RGB"))
|
| 217 |
+
# Video (T,H,W,3|4) uint8
|
| 218 |
+
if x.ndim == 4 and x.shape[-1] in (3, 4) and x.dtype == _np.uint8:
|
| 219 |
+
# Pass frames straight to the processor — no mp4 round-trip, no
|
| 220 |
+
# av/imageio needed. Drop alpha if present.
|
| 221 |
+
return ("video", x if x.shape[-1] == 3 else x[..., :3])
|
| 222 |
+
# Audio multichannel 2D float -> mono mixdown
|
| 223 |
+
if x.ndim == 2 and _np.issubdtype(x.dtype, _np.floating):
|
| 224 |
+
audio = x.mean(axis=0 if x.shape[0] <= 8 else 1).astype(_np.float32)
|
| 225 |
+
return ("audio", audio)
|
| 226 |
+
|
| 227 |
+
# torch.Tensor -> numpy and recurse
|
| 228 |
+
try:
|
| 229 |
+
import torch as _torch
|
| 230 |
+
except ImportError:
|
| 231 |
+
_torch = None
|
| 232 |
+
if _torch is not None and isinstance(x, _torch.Tensor):
|
| 233 |
+
return _resolve_input(x.detach().cpu().numpy())
|
| 234 |
+
|
| 235 |
+
# bytes / BytesIO / file-like
|
| 236 |
+
if isinstance(x, (bytes, bytearray)):
|
| 237 |
+
data = bytes(x)
|
| 238 |
+
elif isinstance(x, io.IOBase):
|
| 239 |
+
data = x.read()
|
| 240 |
+
else:
|
| 241 |
+
data = None
|
| 242 |
+
|
| 243 |
+
if data is not None:
|
| 244 |
+
kind = _sniff_media_type_bytes(data[:4096])
|
| 245 |
+
if kind == "image":
|
| 246 |
+
_PILImage = _pil_image()
|
| 247 |
+
return ("image", _PILImage.open(io.BytesIO(data)).convert("RGB"))
|
| 248 |
+
if kind == "svg":
|
| 249 |
+
return ("image", _svg_to_image(bytes(data)))
|
| 250 |
+
if kind in ("video", "audio"):
|
| 251 |
+
import tempfile as _tf
|
| 252 |
+
ext = ".mp4" if kind == "video" else ".wav"
|
| 253 |
+
tf = _tf.NamedTemporaryFile(suffix=ext, delete=False)
|
| 254 |
+
tf.write(data); tf.close()
|
| 255 |
+
return (kind, tf.name)
|
| 256 |
+
if kind == "pdf":
|
| 257 |
+
# pypdfium2 reads bytes directly — no temp file needed.
|
| 258 |
+
return ("pdf", bytes(data))
|
| 259 |
+
|
| 260 |
+
if isinstance(x, str):
|
| 261 |
+
local = _download_if_url(x)
|
| 262 |
+
if _os.path.isfile(local):
|
| 263 |
+
kind = _sniff_media_type(local)
|
| 264 |
+
if kind == "image":
|
| 265 |
+
_PILImage = _pil_image()
|
| 266 |
+
return ("image", _PILImage.open(local).convert("RGB"))
|
| 267 |
+
if kind == "svg":
|
| 268 |
+
return ("image", _svg_to_image(local))
|
| 269 |
+
if kind in ("video", "audio", "pdf"):
|
| 270 |
+
return (kind, local)
|
| 271 |
+
return ("text", x)
|
| 272 |
+
|
| 273 |
+
return ("text", str(x))
|
| 274 |
+
|
| 275 |
+
|
| 276 |
+
def _is_media_string(x) -> bool:
|
| 277 |
+
if not isinstance(x, str):
|
| 278 |
+
return False
|
| 279 |
+
return _resolve_input(x)[0] in ("image", "video", "audio", "pdf")
|
| 280 |
+
|
| 281 |
+
|
| 282 |
+
def _prompt_from_kwargs(st_model, kwargs):
|
| 283 |
+
prompt = kwargs.get("prompt")
|
| 284 |
+
if prompt is None:
|
| 285 |
+
prompt_name = kwargs.get("prompt_name") or getattr(st_model, "default_prompt_name", None)
|
| 286 |
+
prompt = (getattr(st_model, "prompts", {}) or {}).get(prompt_name, "") if prompt_name else ""
|
| 287 |
+
return prompt or ""
|
| 288 |
+
|
| 289 |
+
|
| 290 |
+
def _raw_media_parts(st_model, value, kwargs):
|
| 291 |
+
prompt = _prompt_from_kwargs(st_model, kwargs)
|
| 292 |
+
return (prompt, value) if prompt else (value,)
|
| 293 |
+
|
| 294 |
+
|
| 295 |
+
def _prompted_parts(st_model, value, kwargs):
|
| 296 |
+
parts = value if isinstance(value, tuple) else (value,)
|
| 297 |
+
prompt = _prompt_from_kwargs(st_model, kwargs)
|
| 298 |
+
return (prompt, *parts) if prompt else parts
|
| 299 |
+
|
| 300 |
+
|
| 301 |
+
def _align_eval_processor(processor):
|
| 302 |
+
video_processor = getattr(processor, "video_processor", None)
|
| 303 |
+
if video_processor is None:
|
| 304 |
+
return
|
| 305 |
+
if hasattr(video_processor, "do_sample_frames"):
|
| 306 |
+
video_processor.do_sample_frames = False
|
| 307 |
+
for attr in ("max_frames", "num_frames"):
|
| 308 |
+
if hasattr(video_processor, attr):
|
| 309 |
+
setattr(video_processor, attr, EVAL_VIDEO_NUM_FRAMES)
|
| 310 |
+
if hasattr(video_processor, "size") and isinstance(video_processor.size, dict):
|
| 311 |
+
video_processor.size = {
|
| 312 |
+
**video_processor.size,
|
| 313 |
+
"longest_edge": EVAL_VIDEO_MAX_PIXELS,
|
| 314 |
+
"shortest_edge": EVAL_IMAGE_MIN_PIXELS,
|
| 315 |
+
}
|
| 316 |
+
if hasattr(video_processor, "max_pixels"):
|
| 317 |
+
video_processor.max_pixels = EVAL_VIDEO_MAX_PIXELS
|
| 318 |
+
if hasattr(video_processor, "min_pixels"):
|
| 319 |
+
video_processor.min_pixels = EVAL_IMAGE_MIN_PIXELS
|
| 320 |
+
|
| 321 |
+
|
| 322 |
+
def _build_eval_image_prompt(processor, prefix: str = ""):
|
| 323 |
+
image_token = getattr(processor, "image_token", IMAGE_PROMPT)
|
| 324 |
+
text = f"{prefix or ''}<|vision_start|>{image_token}<|vision_end|>"
|
| 325 |
+
try:
|
| 326 |
+
return processor.apply_chat_template(
|
| 327 |
+
[{"role": "user", "content": text}],
|
| 328 |
+
tokenize=False,
|
| 329 |
+
add_generation_prompt=False,
|
| 330 |
+
)
|
| 331 |
+
except (ValueError, AttributeError):
|
| 332 |
+
return f"{prefix or ''}{IMAGE_PROMPT}"
|
| 333 |
+
|
| 334 |
+
|
| 335 |
+
def _audio_output_length(feature_attention_mask):
|
| 336 |
+
real_frames = feature_attention_mask.sum(-1)
|
| 337 |
+
aftercnn = (real_frames - 1) // 2 + 1
|
| 338 |
+
return int(((aftercnn - 2) // 2 + 1).item())
|
| 339 |
+
|
| 340 |
+
|
| 341 |
+
def _load_audio_array(audio_input):
|
| 342 |
+
import numpy as np
|
| 343 |
+
|
| 344 |
+
if isinstance(audio_input, _AudioWrapper):
|
| 345 |
+
return audio_input.array.astype(np.float32), audio_input.sampling_rate
|
| 346 |
+
if isinstance(audio_input, str):
|
| 347 |
+
try:
|
| 348 |
+
import librosa
|
| 349 |
+
except ImportError as e:
|
| 350 |
+
raise ImportError(
|
| 351 |
+
"Loading audio from a file path needs `pip install librosa`"
|
| 352 |
+
" (or pass a 1-D numpy float32 waveform at 16 kHz)."
|
| 353 |
+
) from e
|
| 354 |
+
audio, sr = librosa.load(audio_input, sr=16000)
|
| 355 |
+
return audio.astype(np.float32), sr
|
| 356 |
+
if isinstance(audio_input, np.ndarray):
|
| 357 |
+
return audio_input.astype(np.float32), 16000
|
| 358 |
+
raise TypeError(f"Unsupported audio input type: {type(audio_input)}")
|
| 359 |
+
|
| 360 |
+
|
| 361 |
+
def _build_audio_model_inputs(owner, audio_input, device, prefix: str = ""):
|
| 362 |
+
import numpy as np
|
| 363 |
+
from transformers import WhisperFeatureExtractor
|
| 364 |
+
|
| 365 |
+
audio, sr = _load_audio_array(audio_input)
|
| 366 |
+
if not np.isfinite(audio).all():
|
| 367 |
+
audio = np.nan_to_num(audio, nan=0.0, posinf=0.0, neginf=0.0)
|
| 368 |
+
peak = float(np.max(np.abs(audio))) if audio.size else 0.0
|
| 369 |
+
if peak > 1.0:
|
| 370 |
+
audio = audio / peak
|
| 371 |
+
|
| 372 |
+
feat_ext = WhisperFeatureExtractor(feature_size=128)
|
| 373 |
+
audio_inputs = feat_ext(
|
| 374 |
+
audio,
|
| 375 |
+
sampling_rate=sr,
|
| 376 |
+
return_tensors="pt",
|
| 377 |
+
padding="max_length",
|
| 378 |
+
return_attention_mask=True,
|
| 379 |
+
)
|
| 380 |
+
input_features = audio_inputs["input_features"]
|
| 381 |
+
feature_attention_mask = audio_inputs["attention_mask"]
|
| 382 |
+
n_tokens = _audio_output_length(feature_attention_mask)
|
| 383 |
+
|
| 384 |
+
start = owner.tokenizer.convert_ids_to_tokens(owner.config.audio_start_token_id)
|
| 385 |
+
token = owner.tokenizer.convert_ids_to_tokens(owner.config.audio_token_id)
|
| 386 |
+
end = owner.tokenizer.convert_ids_to_tokens(owner.config.audio_end_token_id)
|
| 387 |
+
audio_seq = start + token * n_tokens + end
|
| 388 |
+
text = f"{prefix or ''}{audio_seq}"
|
| 389 |
+
try:
|
| 390 |
+
prompt = owner.processor.apply_chat_template(
|
| 391 |
+
[{"role": "user", "content": text}],
|
| 392 |
+
tokenize=False,
|
| 393 |
+
add_generation_prompt=False,
|
| 394 |
+
)
|
| 395 |
+
except (ValueError, AttributeError):
|
| 396 |
+
prompt = text
|
| 397 |
+
|
| 398 |
+
out = owner.processor(text=[prompt], return_tensors="pt", padding=False, truncation=False)
|
| 399 |
+
model_dtype = next(owner.model.parameters()).dtype
|
| 400 |
+
inputs = {k: v.to(device) for k, v in out.items() if torch.is_tensor(v)}
|
| 401 |
+
inputs["input_features"] = input_features.to(device=device, dtype=model_dtype)
|
| 402 |
+
inputs["feature_attention_mask"] = feature_attention_mask.to(device)
|
| 403 |
+
pos_builder = globals().get("_get_1d_position_ids")
|
| 404 |
+
if pos_builder is not None:
|
| 405 |
+
inputs["position_ids"] = pos_builder(inputs["attention_mask"])
|
| 406 |
+
return inputs
|
| 407 |
+
|
| 408 |
+
|
| 409 |
+
def _extract_audio_from_video(video_path):
|
| 410 |
+
"""Return mono float32 audio @ 16 kHz decoded from the video's audio track, or
|
| 411 |
+
None if no audio stream is present. PyAV is already a dep for video decoding."""
|
| 412 |
+
try:
|
| 413 |
+
import av
|
| 414 |
+
import numpy as np
|
| 415 |
+
from av.audio.resampler import AudioResampler
|
| 416 |
+
except ImportError:
|
| 417 |
+
return None
|
| 418 |
+
container = av.open(video_path)
|
| 419 |
+
try:
|
| 420 |
+
audio_stream = next((s for s in container.streams if s.type == "audio"), None)
|
| 421 |
+
if audio_stream is None:
|
| 422 |
+
return None
|
| 423 |
+
resampler = AudioResampler(format="flt", layout="mono", rate=16000)
|
| 424 |
+
samples = []
|
| 425 |
+
for frame in container.decode(audio=0):
|
| 426 |
+
for rf in resampler.resample(frame):
|
| 427 |
+
samples.append(rf.to_ndarray().flatten())
|
| 428 |
+
for rf in resampler.resample(None):
|
| 429 |
+
samples.append(rf.to_ndarray().flatten())
|
| 430 |
+
if not samples:
|
| 431 |
+
return None
|
| 432 |
+
return np.concatenate(samples).astype(np.float32)
|
| 433 |
+
finally:
|
| 434 |
+
container.close()
|
| 435 |
+
|
| 436 |
+
|
| 437 |
+
def _eval_video_frames(video_path):
|
| 438 |
+
if not isinstance(video_path, str):
|
| 439 |
+
return video_path
|
| 440 |
+
try:
|
| 441 |
+
import av
|
| 442 |
+
import numpy as np
|
| 443 |
+
except ImportError:
|
| 444 |
+
return video_path
|
| 445 |
+
container = av.open(video_path)
|
| 446 |
+
try:
|
| 447 |
+
frames = [frame.to_image().convert("RGB") for frame in container.decode(video=0)]
|
| 448 |
+
finally:
|
| 449 |
+
container.close()
|
| 450 |
+
if not frames:
|
| 451 |
+
return video_path
|
| 452 |
+
if len(frames) <= EVAL_VIDEO_NUM_FRAMES:
|
| 453 |
+
return frames
|
| 454 |
+
indices = np.linspace(0, len(frames) - 1, EVAL_VIDEO_NUM_FRAMES, dtype=int).tolist()
|
| 455 |
+
return [frames[i] for i in indices]
|
| 456 |
+
|
| 457 |
+
|
| 458 |
+
def _pdf_to_images(pdf, dpi: int = PDF_DPI):
|
| 459 |
+
"""Rasterise every page of a PDF to a list of PIL.Image (RGB).
|
| 460 |
+
|
| 461 |
+
`pdf` may be a path, raw bytes, BytesIO, or an existing list of PIL.Images
|
| 462 |
+
(returned as-is). Lazy-imports `pypdfium2` so users who never touch PDFs
|
| 463 |
+
are not forced to install it.
|
| 464 |
+
"""
|
| 465 |
+
_PILImage = _pil_image() # PIL is a hard dep of the image path
|
| 466 |
+
if isinstance(pdf, list) and pdf and all(isinstance(p, _PILImage.Image) for p in pdf):
|
| 467 |
+
return pdf
|
| 468 |
+
try:
|
| 469 |
+
import pypdfium2 as pdfium
|
| 470 |
+
except ImportError as e:
|
| 471 |
+
raise ImportError(
|
| 472 |
+
"Decoding PDF pages needs `pip install pypdfium2`."
|
| 473 |
+
) from e
|
| 474 |
+
import io as _io
|
| 475 |
+
if isinstance(pdf, (bytes, bytearray)):
|
| 476 |
+
doc = pdfium.PdfDocument(bytes(pdf))
|
| 477 |
+
elif isinstance(pdf, _io.IOBase):
|
| 478 |
+
doc = pdfium.PdfDocument(pdf.read())
|
| 479 |
+
else:
|
| 480 |
+
doc = pdfium.PdfDocument(pdf)
|
| 481 |
+
scale = dpi / 72.0
|
| 482 |
+
pages = []
|
| 483 |
+
try:
|
| 484 |
+
for page in doc:
|
| 485 |
+
pil = page.render(scale=scale).to_pil().convert("RGB")
|
| 486 |
+
pages.append(pil)
|
| 487 |
+
finally:
|
| 488 |
+
doc.close()
|
| 489 |
+
return pages
|
| 490 |
+
|
| 491 |
+
|
| 492 |
+
def _patch_st_encode_multipart():
|
| 493 |
+
"""Intercept ST.encode for multipart tuple inputs so PIL.Image and
|
| 494 |
+
np.ndarray media parts bypass ST's length-sort."""
|
| 495 |
+
import importlib
|
| 496 |
+
import torch
|
| 497 |
+
try:
|
| 498 |
+
st_mod = importlib.import_module("sentence_transformers.SentenceTransformer")
|
| 499 |
+
except ImportError:
|
| 500 |
+
return
|
| 501 |
+
_ST = st_mod.SentenceTransformer
|
| 502 |
+
if getattr(_ST.encode, "_omni_multipart_patched", False):
|
| 503 |
+
return
|
| 504 |
+
_orig = _ST.encode
|
| 505 |
+
|
| 506 |
+
def _encode(self, sentences, *args, **kwargs):
|
| 507 |
+
def _is_nonstring_input(x):
|
| 508 |
+
# anything other than a pure string becomes a 1-part multipart item
|
| 509 |
+
return not isinstance(x, str)
|
| 510 |
+
single_bare = _is_nonstring_input(sentences) and not isinstance(sentences, list)
|
| 511 |
+
list_with_nonstr = (isinstance(sentences, list) and sentences
|
| 512 |
+
and any(_is_nonstring_input(s) for s in sentences))
|
| 513 |
+
single_media_string = isinstance(sentences, str) and _is_media_string(sentences)
|
| 514 |
+
list_with_media_string = (isinstance(sentences, list) and sentences
|
| 515 |
+
and any(isinstance(s, str) and _is_media_string(s) for s in sentences))
|
| 516 |
+
fwd_keys = getattr(self[0], "forward_kwargs", set())
|
| 517 |
+
forward_kwargs = {k: kwargs[k] for k in fwd_keys if k in kwargs}
|
| 518 |
+
if single_media_string or list_with_media_string:
|
| 519 |
+
if single_media_string:
|
| 520 |
+
batch = [_raw_media_parts(self, sentences, kwargs)]
|
| 521 |
+
else:
|
| 522 |
+
batch = [_raw_media_parts(self, s, kwargs) for s in sentences]
|
| 523 |
+
features = {"_multipart_batch": batch, "_is_multipart_batch": True}
|
| 524 |
+
with torch.no_grad():
|
| 525 |
+
out = self[0](features, **forward_kwargs)
|
| 526 |
+
emb = out["sentence_embedding"]
|
| 527 |
+
if kwargs.get("convert_to_numpy", True):
|
| 528 |
+
emb = emb.detach().cpu().float().numpy()
|
| 529 |
+
if single_media_string:
|
| 530 |
+
emb = emb[0] if hasattr(emb, "__getitem__") else emb
|
| 531 |
+
return emb
|
| 532 |
+
if single_bare or list_with_nonstr:
|
| 533 |
+
if single_bare:
|
| 534 |
+
batch = [_prompted_parts(self, sentences, kwargs)]
|
| 535 |
+
else:
|
| 536 |
+
batch = [_prompted_parts(self, s, kwargs) for s in sentences]
|
| 537 |
+
features = {"_multipart_batch": batch, "_is_multipart_batch": True}
|
| 538 |
+
with torch.no_grad():
|
| 539 |
+
out = self[0](features, **forward_kwargs)
|
| 540 |
+
emb = out["sentence_embedding"]
|
| 541 |
+
if kwargs.get("convert_to_numpy", True):
|
| 542 |
+
emb = emb.detach().cpu().float().numpy()
|
| 543 |
+
if single_bare:
|
| 544 |
+
emb = emb[0] if hasattr(emb, "__getitem__") else emb
|
| 545 |
+
return emb
|
| 546 |
+
result = _orig(self, sentences, *args, **kwargs)
|
| 547 |
+
# ST 5.x applies truncate_dim without L2 renormalization; the README
|
| 548 |
+
# promises unit-norm truncated embeddings, so restore that here.
|
| 549 |
+
if kwargs.get("truncate_dim") is not None and not kwargs.get("normalize_embeddings", False):
|
| 550 |
+
import numpy as _np
|
| 551 |
+
if torch.is_tensor(result):
|
| 552 |
+
result = torch.nn.functional.normalize(result, p=2, dim=-1)
|
| 553 |
+
elif isinstance(result, _np.ndarray):
|
| 554 |
+
n = _np.linalg.norm(result, axis=-1, keepdims=True) + 1e-12
|
| 555 |
+
result = result / n
|
| 556 |
+
return result
|
| 557 |
+
|
| 558 |
+
_encode._omni_multipart_patched = True
|
| 559 |
+
_ST.encode = _encode
|
| 560 |
+
|
| 561 |
+
def encode_query(self, sentences, *args, **kwargs):
|
| 562 |
+
kwargs.setdefault("prompt_name", "query")
|
| 563 |
+
return self.encode(sentences, *args, **kwargs)
|
| 564 |
+
|
| 565 |
+
def encode_document(self, sentences, *args, **kwargs):
|
| 566 |
+
kwargs.setdefault("prompt_name", "document")
|
| 567 |
+
return self.encode(sentences, *args, **kwargs)
|
| 568 |
+
|
| 569 |
+
_ST.encode_query = encode_query
|
| 570 |
+
_ST.encode_document = encode_document
|
| 571 |
+
|
| 572 |
+
|
| 573 |
+
_patch_st_encode_multipart()
|
| 574 |
+
|
| 575 |
+
|
| 576 |
+
class Transformer(nn.Module):
|
| 577 |
+
save_in_root: bool = True
|
| 578 |
+
# Tells sentence-transformers to thread these kwargs from encode() through
|
| 579 |
+
# to our forward() — otherwise ST filters unknown kwargs out.
|
| 580 |
+
forward_kwargs = {"task", "truncate_dim"}
|
| 581 |
+
|
| 582 |
+
def __init__(
|
| 583 |
+
self,
|
| 584 |
+
model_name_or_path: str = "jinaai/jina-embeddings-v5-omni-nano",
|
| 585 |
+
max_seq_length: Optional[int] = None,
|
| 586 |
+
config_args: Optional[Dict[str, Any]] = None,
|
| 587 |
+
model_args: Optional[Dict[str, Any]] = None,
|
| 588 |
+
tokenizer_args: Optional[Dict[str, Any]] = None,
|
| 589 |
+
cache_dir: Optional[str] = None,
|
| 590 |
+
backend: str = "torch",
|
| 591 |
+
task: Optional[str] = None,
|
| 592 |
+
default_task: Optional[str] = None,
|
| 593 |
+
**kwargs,
|
| 594 |
+
) -> None:
|
| 595 |
+
super().__init__()
|
| 596 |
+
if backend != "torch":
|
| 597 |
+
raise ValueError(
|
| 598 |
+
f"Backend '{backend}' is not supported, please use 'torch' instead"
|
| 599 |
+
)
|
| 600 |
+
|
| 601 |
+
config_kwargs = dict(config_args or {})
|
| 602 |
+
model_kwargs = dict(model_args or {})
|
| 603 |
+
tokenizer_kwargs = dict(tokenizer_args or {})
|
| 604 |
+
|
| 605 |
+
# Default-task resolution precedence (highest to lowest):
|
| 606 |
+
# 1. `task` / `default_task` kwarg to this __init__
|
| 607 |
+
# 2. `model_args={'default_task': ...}` (legacy path)
|
| 608 |
+
# 3. JINA_V5_TASK env var
|
| 609 |
+
# 4. unset -> encode() must pass task=
|
| 610 |
+
self.default_task = (
|
| 611 |
+
task
|
| 612 |
+
or default_task
|
| 613 |
+
or model_kwargs.pop("default_task", None)
|
| 614 |
+
or os.environ.get("JINA_V5_TASK")
|
| 615 |
+
)
|
| 616 |
+
if self.default_task and self.default_task not in TASK_NAMES:
|
| 617 |
+
raise ValueError(
|
| 618 |
+
f"Invalid task: {self.default_task}. Must be one of {TASK_NAMES}."
|
| 619 |
+
)
|
| 620 |
+
|
| 621 |
+
# setdefault so caller-provided trust_remote_code isn't duplicated
|
| 622 |
+
config_kwargs.setdefault("trust_remote_code", True)
|
| 623 |
+
model_kwargs.setdefault("trust_remote_code", True)
|
| 624 |
+
tokenizer_kwargs.setdefault("trust_remote_code", True)
|
| 625 |
+
# Dedupe cache_dir: we pass it explicitly below, so strip any copy
|
| 626 |
+
# that sentence-transformers may have also threaded through *_args.
|
| 627 |
+
for _kw in (config_kwargs, model_kwargs, tokenizer_kwargs):
|
| 628 |
+
_kw.pop("cache_dir", None)
|
| 629 |
+
|
| 630 |
+
self.config = AutoConfig.from_pretrained(
|
| 631 |
+
model_name_or_path, cache_dir=cache_dir, **config_kwargs
|
| 632 |
+
)
|
| 633 |
+
self.model = AutoModel.from_pretrained(
|
| 634 |
+
model_name_or_path, cache_dir=cache_dir, **model_kwargs,
|
| 635 |
+
)
|
| 636 |
+
self.tokenizer = self.model.tokenizer
|
| 637 |
+
# AutoProcessor pulls in PIL transitively; lazy-import so users on
|
| 638 |
+
# text-only setups (no pillow installed) can still load the model.
|
| 639 |
+
try:
|
| 640 |
+
from transformers import AutoProcessor as _AutoProcessor
|
| 641 |
+
processor_kwargs = dict(tokenizer_kwargs)
|
| 642 |
+
processor_kwargs.setdefault("min_pixels", EVAL_IMAGE_MIN_PIXELS)
|
| 643 |
+
processor_kwargs.setdefault("max_pixels", EVAL_IMAGE_MAX_PIXELS)
|
| 644 |
+
self.processor = _AutoProcessor.from_pretrained(
|
| 645 |
+
model_name_or_path, cache_dir=cache_dir, **processor_kwargs,
|
| 646 |
+
)
|
| 647 |
+
_align_eval_processor(self.processor)
|
| 648 |
+
except Exception:
|
| 649 |
+
self.processor = None
|
| 650 |
+
|
| 651 |
+
tc = getattr(self.config, "text_config", self.config)
|
| 652 |
+
max_pos = getattr(tc, "max_position_embeddings", MAX_SEQ_LENGTH)
|
| 653 |
+
self.max_seq_length = max_seq_length or min(max_pos, MAX_SEQ_LENGTH)
|
| 654 |
+
|
| 655 |
+
def tokenize(
|
| 656 |
+
self,
|
| 657 |
+
texts: Union[List[str], List[Dict], list],
|
| 658 |
+
padding: Union[str, bool] = True,
|
| 659 |
+
**kwargs,
|
| 660 |
+
) -> Dict[str, torch.Tensor]:
|
| 661 |
+
if texts and any(isinstance(t, tuple) for t in texts):
|
| 662 |
+
# Wrap non-tuple entries as 1-tuples so every batch slot goes
|
| 663 |
+
# through _encode_parts. Lets users mix: [(t,img), "plain text"].
|
| 664 |
+
wrapped = [t if isinstance(t, tuple) else (t,) for t in texts]
|
| 665 |
+
return {"_multipart_batch": wrapped, "_is_multipart_batch": True}
|
| 666 |
+
resolved = [_resolve_input(t) for t in texts]
|
| 667 |
+
# Heterogeneous batch (e.g. ["speech.wav", "plain text"]) — route through
|
| 668 |
+
# the multipart path where each element is dispatched on its own kind.
|
| 669 |
+
if len({k for k, _ in resolved}) > 1:
|
| 670 |
+
wrapped = [t if isinstance(t, tuple) else (t,) for t in texts]
|
| 671 |
+
return {"_multipart_batch": wrapped, "_is_multipart_batch": True}
|
| 672 |
+
first_kind = resolved[0][0]
|
| 673 |
+
values = [v for _, v in resolved]
|
| 674 |
+
|
| 675 |
+
if first_kind == "image":
|
| 676 |
+
return {"_images": values, "_is_image_batch": True}
|
| 677 |
+
if first_kind == "video":
|
| 678 |
+
return {"_video_paths": values, "_is_video_batch": True}
|
| 679 |
+
if first_kind == "audio":
|
| 680 |
+
return {"_audio_paths": values, "_is_audio_batch": True}
|
| 681 |
+
if first_kind == "pdf":
|
| 682 |
+
return {"_pdfs": values, "_is_pdf_batch": True}
|
| 683 |
+
|
| 684 |
+
if isinstance(texts[0], dict):
|
| 685 |
+
texts = [next(iter(t.values())) for t in texts]
|
| 686 |
+
elif isinstance(texts[0], (list, tuple)):
|
| 687 |
+
texts = [t[0] for t in texts]
|
| 688 |
+
|
| 689 |
+
return self.tokenizer(
|
| 690 |
+
[str(s) for s in texts],
|
| 691 |
+
max_length=self.max_seq_length,
|
| 692 |
+
truncation=True,
|
| 693 |
+
padding=padding,
|
| 694 |
+
return_tensors="pt",
|
| 695 |
+
)
|
| 696 |
+
|
| 697 |
+
def _resolve_task(self, task: Optional[str]) -> str:
|
| 698 |
+
if task is None:
|
| 699 |
+
if self.default_task is None:
|
| 700 |
+
raise ValueError(
|
| 701 |
+
"Task must be specified. Set it during loading "
|
| 702 |
+
"(model_kwargs={'default_task': 'retrieval'}) or pass "
|
| 703 |
+
"task='retrieval' to encode()."
|
| 704 |
+
)
|
| 705 |
+
task = self.default_task
|
| 706 |
+
if task not in TASK_NAMES:
|
| 707 |
+
raise ValueError(f"Invalid task: {task}. Must be one of {TASK_NAMES}.")
|
| 708 |
+
return task
|
| 709 |
+
|
| 710 |
+
def _last_token_pool(self, hidden, attention_mask):
|
| 711 |
+
seq_lens = attention_mask.sum(dim=1) - 1
|
| 712 |
+
pooled = hidden[torch.arange(hidden.shape[0], device=hidden.device), seq_lens]
|
| 713 |
+
return F.normalize(pooled, p=2, dim=-1).float()
|
| 714 |
+
|
| 715 |
+
def _encode_single_image(self, image, device, prefix: str = "") -> torch.Tensor:
|
| 716 |
+
prompt = _build_eval_image_prompt(self.processor, prefix=prefix)
|
| 717 |
+
inputs = self.processor(images=image, text=prompt, return_tensors="pt", truncation=False)
|
| 718 |
+
inputs = {k: v.to(device) for k, v in inputs.items() if torch.is_tensor(v)}
|
| 719 |
+
with torch.no_grad():
|
| 720 |
+
hidden = self.model(**inputs).last_hidden_state
|
| 721 |
+
return self._last_token_pool(hidden, inputs["attention_mask"]).squeeze(0)
|
| 722 |
+
|
| 723 |
+
def _encode_single_video(self, video_path, device) -> torch.Tensor:
|
| 724 |
+
video = _eval_video_frames(video_path)
|
| 725 |
+
inputs = self.processor(videos=video, text=VIDEO_PROMPT, return_tensors="pt", truncation=False)
|
| 726 |
+
inputs = {k: v.to(device) for k, v in inputs.items() if torch.is_tensor(v)}
|
| 727 |
+
with torch.no_grad():
|
| 728 |
+
hidden = self.model(**inputs).last_hidden_state
|
| 729 |
+
return self._last_token_pool(hidden, inputs["attention_mask"]).squeeze(0)
|
| 730 |
+
|
| 731 |
+
def _encode_single_audio(self, audio_input, device, prefix: str = "") -> torch.Tensor:
|
| 732 |
+
inputs = _build_audio_model_inputs(self, audio_input, device, prefix=prefix)
|
| 733 |
+
with torch.no_grad():
|
| 734 |
+
hidden = self.model(**inputs).last_hidden_state
|
| 735 |
+
return self._last_token_pool(hidden, inputs["attention_mask"]).squeeze(0)
|
| 736 |
+
|
| 737 |
+
def _encode_single_pdf(self, pdf, device) -> torch.Tensor:
|
| 738 |
+
"""Encode a PDF as a fused sequence of page images (single embedding).
|
| 739 |
+
|
| 740 |
+
Pages are rasterised with pypdfium2 then fed through the same
|
| 741 |
+
multipart fusion path used for tuples — so a 3-page PDF produces
|
| 742 |
+
a single embedding spanning all three rendered pages.
|
| 743 |
+
"""
|
| 744 |
+
pages = _pdf_to_images(pdf)
|
| 745 |
+
if not pages:
|
| 746 |
+
raise ValueError("PDF has 0 pages — nothing to encode.")
|
| 747 |
+
return self._encode_parts(tuple(pages), device)
|
| 748 |
+
|
| 749 |
+
def _encode_composite_parts(self, expanded, device) -> torch.Tensor:
|
| 750 |
+
import numpy as np
|
| 751 |
+
from transformers import WhisperFeatureExtractor
|
| 752 |
+
|
| 753 |
+
content = []
|
| 754 |
+
images, videos = [], []
|
| 755 |
+
audio_features, feature_masks = [], []
|
| 756 |
+
feat_ext = None
|
| 757 |
+
for kind, p in expanded:
|
| 758 |
+
if kind == "text":
|
| 759 |
+
content.append({"type": "text", "text": str(p)})
|
| 760 |
+
elif kind == "image":
|
| 761 |
+
content.append({"type": "image"})
|
| 762 |
+
images.append(p)
|
| 763 |
+
elif kind == "video":
|
| 764 |
+
content.append({"type": "video"})
|
| 765 |
+
videos.append(_eval_video_frames(p) if isinstance(p, str) else p)
|
| 766 |
+
elif kind == "audio":
|
| 767 |
+
if feat_ext is None:
|
| 768 |
+
feat_ext = WhisperFeatureExtractor(feature_size=128)
|
| 769 |
+
audio_arr, sr = _load_audio_array(p)
|
| 770 |
+
if not np.isfinite(audio_arr).all():
|
| 771 |
+
audio_arr = np.nan_to_num(audio_arr, nan=0.0, posinf=0.0, neginf=0.0)
|
| 772 |
+
peak = float(np.max(np.abs(audio_arr))) if audio_arr.size else 0.0
|
| 773 |
+
if peak > 1.0:
|
| 774 |
+
audio_arr = audio_arr / peak
|
| 775 |
+
audio_inputs = feat_ext(
|
| 776 |
+
audio_arr,
|
| 777 |
+
sampling_rate=sr,
|
| 778 |
+
return_tensors="pt",
|
| 779 |
+
padding="max_length",
|
| 780 |
+
return_attention_mask=True,
|
| 781 |
+
)
|
| 782 |
+
feat_mask = audio_inputs["attention_mask"]
|
| 783 |
+
n_tokens = _audio_output_length(feat_mask)
|
| 784 |
+
start = self.tokenizer.convert_ids_to_tokens(self.config.audio_start_token_id)
|
| 785 |
+
token = self.tokenizer.convert_ids_to_tokens(self.config.audio_token_id)
|
| 786 |
+
end = self.tokenizer.convert_ids_to_tokens(self.config.audio_end_token_id)
|
| 787 |
+
content.append({"type": "text", "text": start + token * n_tokens + end})
|
| 788 |
+
audio_features.append(audio_inputs["input_features"])
|
| 789 |
+
feature_masks.append(feat_mask)
|
| 790 |
+
|
| 791 |
+
has_chat_template = getattr(self.processor, "chat_template", None) is not None
|
| 792 |
+
if has_chat_template:
|
| 793 |
+
prompt = self.processor.apply_chat_template(
|
| 794 |
+
[{"role": "user", "content": content}],
|
| 795 |
+
tokenize=False,
|
| 796 |
+
add_generation_prompt=False,
|
| 797 |
+
)
|
| 798 |
+
if images or videos:
|
| 799 |
+
image_token = getattr(self.processor, "image_token", "<|image_pad|>")
|
| 800 |
+
video_token = getattr(self.processor, "video_token", "<|video_pad|>")
|
| 801 |
+
flat = []
|
| 802 |
+
for c in content:
|
| 803 |
+
if c.get("type") == "text":
|
| 804 |
+
flat.append(c["text"])
|
| 805 |
+
elif c.get("type") == "image":
|
| 806 |
+
flat.append(f"<|vision_start|>{image_token}<|vision_end|>")
|
| 807 |
+
elif c.get("type") == "video":
|
| 808 |
+
flat.append(f"<|vision_start|>{video_token}<|vision_end|>")
|
| 809 |
+
prompt_flat = self.processor.apply_chat_template(
|
| 810 |
+
[{"role": "user", "content": "".join(flat)}],
|
| 811 |
+
tokenize=False,
|
| 812 |
+
add_generation_prompt=False,
|
| 813 |
+
)
|
| 814 |
+
if "<|vision_start|>" in prompt_flat:
|
| 815 |
+
prompt = prompt_flat
|
| 816 |
+
else:
|
| 817 |
+
pieces = []
|
| 818 |
+
for c in content:
|
| 819 |
+
if c.get("type") == "text":
|
| 820 |
+
pieces.append(c["text"])
|
| 821 |
+
elif c.get("type") == "image":
|
| 822 |
+
pieces.append(IMAGE_PROMPT)
|
| 823 |
+
elif c.get("type") == "video":
|
| 824 |
+
pieces.append(VIDEO_PROMPT)
|
| 825 |
+
prompt = "".join(pieces)
|
| 826 |
+
|
| 827 |
+
proc_kwargs = {"text": [prompt], "return_tensors": "pt", "padding": False, "truncation": False}
|
| 828 |
+
if images:
|
| 829 |
+
proc_kwargs["images"] = images
|
| 830 |
+
if videos:
|
| 831 |
+
proc_kwargs["videos"] = videos
|
| 832 |
+
out = self.processor(**proc_kwargs)
|
| 833 |
+
model_dtype = next(self.model.parameters()).dtype
|
| 834 |
+
inputs = {k: v.to(device) if torch.is_tensor(v) else v for k, v in out.items()}
|
| 835 |
+
if audio_features:
|
| 836 |
+
inputs["input_features"] = torch.cat(audio_features, dim=0).to(device=device, dtype=model_dtype)
|
| 837 |
+
inputs["feature_attention_mask"] = torch.cat(feature_masks, dim=0).to(device)
|
| 838 |
+
|
| 839 |
+
if "Qwen" in type(self.processor).__name__:
|
| 840 |
+
ids = inputs["input_ids"].squeeze(0)
|
| 841 |
+
mm_ids = torch.zeros_like(ids, dtype=torch.int32)
|
| 842 |
+
image_token_id = self.processor.tokenizer.convert_tokens_to_ids(getattr(self.processor, "image_token", "<image>"))
|
| 843 |
+
video_token_id = self.processor.tokenizer.convert_tokens_to_ids(getattr(self.processor, "video_token", "<video>"))
|
| 844 |
+
audio_token_id = self.processor.tokenizer.convert_tokens_to_ids(self.tokenizer.convert_ids_to_tokens(self.config.audio_token_id))
|
| 845 |
+
mm_ids += (ids == image_token_id).to(torch.int32)
|
| 846 |
+
mm_ids += 2 * (ids == video_token_id).to(torch.int32)
|
| 847 |
+
mm_ids += 3 * (ids == audio_token_id).to(torch.int32)
|
| 848 |
+
inputs["mm_token_type_ids"] = mm_ids.unsqueeze(0)
|
| 849 |
+
mask = inputs["attention_mask"]
|
| 850 |
+
pos = mask.long().cumsum(-1) - 1
|
| 851 |
+
pos = pos.masked_fill(mask == 0, 0)
|
| 852 |
+
inputs["position_ids"] = pos.unsqueeze(0).expand(3, -1, -1).contiguous()
|
| 853 |
+
else:
|
| 854 |
+
pos_builder = globals().get("_get_1d_position_ids")
|
| 855 |
+
if pos_builder is not None:
|
| 856 |
+
inputs["position_ids"] = pos_builder(inputs["attention_mask"])
|
| 857 |
+
|
| 858 |
+
with torch.no_grad():
|
| 859 |
+
hidden = self.model(**inputs).last_hidden_state
|
| 860 |
+
return self._last_token_pool(hidden, inputs["attention_mask"]).squeeze(0)
|
| 861 |
+
|
| 862 |
+
def _encode_parts(self, parts, device) -> torch.Tensor:
|
| 863 |
+
"""Fuse a tuple of parts into one embedding in a single forward pass.
|
| 864 |
+
|
| 865 |
+
Each part may be a URL, a local path (sniffed by magic bytes if no
|
| 866 |
+
extension), a PIL.Image, a 1-D numpy audio array, a PDF (rasterised
|
| 867 |
+
to one image per page), or plain text. A video with an audio track
|
| 868 |
+
is auto-expanded to [extracted_audio, video] so the audio tokens
|
| 869 |
+
precede the video tokens.
|
| 870 |
+
"""
|
| 871 |
+
import numpy as np
|
| 872 |
+
from transformers import WhisperFeatureExtractor
|
| 873 |
+
|
| 874 |
+
# Normalize every part first (URL -> path, content-sniff if needed).
|
| 875 |
+
resolved = [_resolve_input(p) for p in parts]
|
| 876 |
+
|
| 877 |
+
# Expand videos-with-audio: prepend extracted audio.
|
| 878 |
+
# Expand PDFs: rasterise into one image-part per page.
|
| 879 |
+
expanded = []
|
| 880 |
+
for kind, value in resolved:
|
| 881 |
+
if kind == "video":
|
| 882 |
+
if isinstance(value, str):
|
| 883 |
+
aud = _extract_audio_from_video(value)
|
| 884 |
+
if aud is not None and aud.size > 0:
|
| 885 |
+
expanded.append(("audio", aud))
|
| 886 |
+
expanded.append(("video", value))
|
| 887 |
+
elif kind == "pdf":
|
| 888 |
+
for page in _pdf_to_images(value):
|
| 889 |
+
expanded.append(("image", page))
|
| 890 |
+
else:
|
| 891 |
+
expanded.append((kind, value))
|
| 892 |
+
|
| 893 |
+
ids_chunks, mask_chunks = [], []
|
| 894 |
+
pix_images, img_grid = [], []
|
| 895 |
+
pix_videos, vid_grid = [], []
|
| 896 |
+
audio_features = []
|
| 897 |
+
feat_ext = None
|
| 898 |
+
|
| 899 |
+
if len(expanded) == 1 and expanded[0][0] == "image":
|
| 900 |
+
return self._encode_single_image(expanded[0][1], device)
|
| 901 |
+
if len(expanded) == 1 and expanded[0][0] == "audio":
|
| 902 |
+
return self._encode_single_audio(expanded[0][1], device)
|
| 903 |
+
if len(expanded) == 2 and expanded[0][0] == "text" and expanded[1][0] == "image":
|
| 904 |
+
return self._encode_single_image(expanded[1][1], device, prefix=str(expanded[0][1]))
|
| 905 |
+
if len(expanded) == 2 and expanded[0][0] == "text" and expanded[1][0] == "audio":
|
| 906 |
+
return self._encode_single_audio(expanded[1][1], device, prefix=str(expanded[0][1]))
|
| 907 |
+
|
| 908 |
+
return self._encode_composite_parts(expanded, device)
|
| 909 |
+
|
| 910 |
+
def forward(
|
| 911 |
+
self,
|
| 912 |
+
features: Dict[str, torch.Tensor],
|
| 913 |
+
task: Optional[str] = None,
|
| 914 |
+
truncate_dim: Optional[int] = None,
|
| 915 |
+
**kwargs,
|
| 916 |
+
) -> Dict[str, torch.Tensor]:
|
| 917 |
+
self.model.eval()
|
| 918 |
+
device = next(self.model.parameters()).device
|
| 919 |
+
task = self._resolve_task(task)
|
| 920 |
+
self.model.set_adapter([task])
|
| 921 |
+
|
| 922 |
+
if features.get("_is_multipart_batch"):
|
| 923 |
+
embs = [self._encode_parts(parts, device) for parts in features["_multipart_batch"]]
|
| 924 |
+
features["sentence_embedding"] = torch.stack(embs)
|
| 925 |
+
return self._maybe_truncate(features, truncate_dim)
|
| 926 |
+
|
| 927 |
+
if features.get("_is_image_batch"):
|
| 928 |
+
embs = [self._encode_single_image(img, device) for img in features["_images"]]
|
| 929 |
+
features["sentence_embedding"] = torch.stack(embs)
|
| 930 |
+
return self._maybe_truncate(features, truncate_dim)
|
| 931 |
+
|
| 932 |
+
if features.get("_is_video_batch"):
|
| 933 |
+
embs = [self._encode_single_video(p, device) for p in features["_video_paths"]]
|
| 934 |
+
features["sentence_embedding"] = torch.stack(embs)
|
| 935 |
+
return self._maybe_truncate(features, truncate_dim)
|
| 936 |
+
|
| 937 |
+
if features.get("_is_audio_batch"):
|
| 938 |
+
embs = [self._encode_single_audio(p, device) for p in features["_audio_paths"]]
|
| 939 |
+
features["sentence_embedding"] = torch.stack(embs)
|
| 940 |
+
return self._maybe_truncate(features, truncate_dim)
|
| 941 |
+
|
| 942 |
+
if features.get("_is_pdf_batch"):
|
| 943 |
+
embs = [self._encode_single_pdf(p, device) for p in features["_pdfs"]]
|
| 944 |
+
features["sentence_embedding"] = torch.stack(embs)
|
| 945 |
+
return self._maybe_truncate(features, truncate_dim)
|
| 946 |
+
|
| 947 |
+
batch = {k: v.to(device) for k, v in features.items() if torch.is_tensor(v)}
|
| 948 |
+
with torch.no_grad():
|
| 949 |
+
hidden = self.model(**batch).last_hidden_state
|
| 950 |
+
|
| 951 |
+
features["sentence_embedding"] = self._last_token_pool(hidden, batch["attention_mask"])
|
| 952 |
+
return self._maybe_truncate(features, truncate_dim)
|
| 953 |
+
|
| 954 |
+
@staticmethod
|
| 955 |
+
def _maybe_truncate(features, truncate_dim):
|
| 956 |
+
# Slicing an L2-normalized vector and renormalizing is equivalent to
|
| 957 |
+
# truncate-then-normalize on the raw pooled vector — so this produces a
|
| 958 |
+
# unit-norm matryoshka embedding.
|
| 959 |
+
if truncate_dim is not None:
|
| 960 |
+
emb = features["sentence_embedding"][..., :truncate_dim]
|
| 961 |
+
features["sentence_embedding"] = F.normalize(emb, p=2, dim=-1)
|
| 962 |
+
return features
|
| 963 |
+
|
| 964 |
+
def get_word_embedding_dimension(self) -> int:
|
| 965 |
+
tc = getattr(self.config, "text_config", self.config)
|
| 966 |
+
return getattr(tc, "hidden_size", 768)
|
| 967 |
+
|
| 968 |
+
def get_sentence_embedding_dimension(self) -> int:
|
| 969 |
+
return self.get_word_embedding_dimension()
|
| 970 |
+
|
| 971 |
+
def get_max_seq_length(self) -> int:
|
| 972 |
+
return self.max_seq_length
|
| 973 |
+
|
| 974 |
+
def save(self, output_path: str, safe_serialization: bool = True, **kwargs) -> None:
|
| 975 |
+
self.model.save_pretrained(output_path, safe_serialization=safe_serialization)
|
| 976 |
+
self.tokenizer.save_pretrained(output_path)
|
| 977 |
+
config = {"max_seq_length": self.max_seq_length}
|
| 978 |
+
with open(os.path.join(output_path, "sentence_bert_config.json"), "w") as f:
|
| 979 |
+
json.dump(config, f, indent=2)
|
| 980 |
+
|
| 981 |
+
@classmethod
|
| 982 |
+
def load(cls, input_path: str) -> "Transformer":
|
| 983 |
+
# Signature must have exactly 1 param so ST routes through the direct
|
| 984 |
+
# constructor path (which maps model_kwargs -> model_args correctly).
|
| 985 |
+
config_path = os.path.join(input_path, "sentence_bert_config.json")
|
| 986 |
+
extra = {}
|
| 987 |
+
if os.path.exists(config_path):
|
| 988 |
+
with open(config_path) as f:
|
| 989 |
+
extra = json.load(f)
|
| 990 |
+
return cls(model_name_or_path=input_path, **extra)
|
model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1b25867d693db0304d5030b8d6ba833b3bc371dc002b2559e49524e0ea405b4b
|
| 3 |
+
size 1972058984
|
modeling_jina_embeddings_v5_omni.py
ADDED
|
@@ -0,0 +1,616 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Unified jina-embeddings-v5-omni-nano: vision + audio + text with task-specific routing.
|
| 3 |
+
|
| 4 |
+
Shared: Qwen3VLVisionModel + Qwen2.5-Omni audio encoder + LlamaModel (EuroBERT, bidirectional)
|
| 5 |
+
Per-task: vision merger, audio projector, special token embeddings, LoRA adapter
|
| 6 |
+
|
| 7 |
+
Modality loading:
|
| 8 |
+
model = AutoModel.from_pretrained(path, trust_remote_code=True) # all components (default)
|
| 9 |
+
model = AutoModel.from_pretrained(path, trust_remote_code=True, modality="vision") # no audio tower/projectors
|
| 10 |
+
model = AutoModel.from_pretrained(path, trust_remote_code=True, modality="audio") # no vision tower/mergers
|
| 11 |
+
|
| 12 |
+
Usage:
|
| 13 |
+
model = AutoModel.from_pretrained("jinaai/jina-embeddings-v5-omni-nano", trust_remote_code=True)
|
| 14 |
+
embeddings = model.encode(["hello world"], task="retrieval")
|
| 15 |
+
"""
|
| 16 |
+
|
| 17 |
+
from typing import List, Optional
|
| 18 |
+
import os
|
| 19 |
+
|
| 20 |
+
import torch
|
| 21 |
+
import torch.nn as nn
|
| 22 |
+
import torch.nn.functional as F
|
| 23 |
+
|
| 24 |
+
from huggingface_hub import snapshot_download
|
| 25 |
+
from transformers import AutoTokenizer, LlamaConfig, PreTrainedModel, PretrainedConfig
|
| 26 |
+
from transformers.modeling_outputs import BaseModelOutputWithPast
|
| 27 |
+
from transformers.models.llama.modeling_llama import LlamaModel
|
| 28 |
+
from transformers.models.qwen3_vl.configuration_qwen3_vl import Qwen3VLVisionConfig
|
| 29 |
+
from transformers.models.qwen3_vl.modeling_qwen3_vl import Qwen3VLVisionModel
|
| 30 |
+
from transformers.models.qwen2_5_omni.configuration_qwen2_5_omni import Qwen2_5OmniAudioEncoderConfig
|
| 31 |
+
from transformers.models.qwen2_5_omni.modeling_qwen2_5_omni import Qwen2_5OmniAudioEncoder
|
| 32 |
+
from peft import PeftMixedModel, PeftConfig
|
| 33 |
+
|
| 34 |
+
TASK_NAMES = ["retrieval", "text-matching", "clustering", "classification"]
|
| 35 |
+
_VALID_MODALITIES = ("omni", "vision", "audio", "text")
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def _key(task):
|
| 39 |
+
return task.replace("-", "_")
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
class PretrainedMerger(nn.Module):
|
| 43 |
+
def __init__(self, hidden_size, out_hidden_size, spatial_merge_size=2):
|
| 44 |
+
super().__init__()
|
| 45 |
+
self.hidden_size = hidden_size * (spatial_merge_size ** 2)
|
| 46 |
+
self.norm = nn.LayerNorm(hidden_size, eps=1e-6)
|
| 47 |
+
self.linear_fc1 = nn.Linear(self.hidden_size, self.hidden_size)
|
| 48 |
+
self.act = nn.GELU()
|
| 49 |
+
self.linear_fc2 = nn.Linear(self.hidden_size, out_hidden_size)
|
| 50 |
+
|
| 51 |
+
def forward(self, x):
|
| 52 |
+
x = self.norm(x)
|
| 53 |
+
x = x.view(-1, self.hidden_size)
|
| 54 |
+
x = self.linear_fc2(self.act(self.linear_fc1(x)))
|
| 55 |
+
return x
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
class JinaEmbeddingsV5OmniConfig(PretrainedConfig):
|
| 59 |
+
model_type = "jina_embeddings_v5_omni"
|
| 60 |
+
|
| 61 |
+
def __init__(
|
| 62 |
+
self,
|
| 63 |
+
vision_config=None,
|
| 64 |
+
text_config=None,
|
| 65 |
+
audio_config=None,
|
| 66 |
+
task_names=None,
|
| 67 |
+
special_token_ids=None,
|
| 68 |
+
image_token_index=None,
|
| 69 |
+
audio_token_id=None,
|
| 70 |
+
audio_start_token_id=None,
|
| 71 |
+
audio_end_token_id=None,
|
| 72 |
+
projector_hidden_act="gelu",
|
| 73 |
+
tie_word_embeddings=False,
|
| 74 |
+
modality="omni",
|
| 75 |
+
**kwargs,
|
| 76 |
+
):
|
| 77 |
+
if isinstance(vision_config, dict):
|
| 78 |
+
vision_config = PretrainedConfig(**vision_config)
|
| 79 |
+
self.vision_config = vision_config or PretrainedConfig()
|
| 80 |
+
if isinstance(text_config, dict):
|
| 81 |
+
text_config = PretrainedConfig(**text_config)
|
| 82 |
+
self.text_config = text_config or PretrainedConfig()
|
| 83 |
+
if isinstance(audio_config, dict):
|
| 84 |
+
audio_config = PretrainedConfig(**audio_config)
|
| 85 |
+
self.audio_config = audio_config or PretrainedConfig()
|
| 86 |
+
self.task_names = task_names or TASK_NAMES
|
| 87 |
+
self.special_token_ids = special_token_ids or []
|
| 88 |
+
self.image_token_index = image_token_index
|
| 89 |
+
self.audio_token_id = audio_token_id
|
| 90 |
+
self.audio_start_token_id = audio_start_token_id
|
| 91 |
+
self.audio_end_token_id = audio_end_token_id
|
| 92 |
+
self.projector_hidden_act = projector_hidden_act
|
| 93 |
+
if modality not in _VALID_MODALITIES:
|
| 94 |
+
raise ValueError(f"modality must be one of {_VALID_MODALITIES}, got '{modality}'")
|
| 95 |
+
self.modality = modality
|
| 96 |
+
super().__init__(tie_word_embeddings=tie_word_embeddings, **kwargs)
|
| 97 |
+
|
| 98 |
+
def get_text_config(self, **kwargs):
|
| 99 |
+
return self.text_config
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
class JinaEmbeddingsV5OmniBase(PreTrainedModel):
|
| 103 |
+
config_class = JinaEmbeddingsV5OmniConfig
|
| 104 |
+
supports_gradient_checkpointing = True
|
| 105 |
+
_supports_sdpa = True
|
| 106 |
+
_supports_flash_attn_2 = True
|
| 107 |
+
_supports_attention_backend = True
|
| 108 |
+
_tied_weights_keys = []
|
| 109 |
+
_keys_to_ignore_on_load_missing = ["lm_head.weight"]
|
| 110 |
+
_keys_to_ignore_on_load_unexpected = []
|
| 111 |
+
|
| 112 |
+
def __init__(self, config: JinaEmbeddingsV5OmniConfig):
|
| 113 |
+
super().__init__(config)
|
| 114 |
+
|
| 115 |
+
modality = getattr(config, "modality", "omni")
|
| 116 |
+
if modality not in _VALID_MODALITIES:
|
| 117 |
+
raise ValueError(f"modality must be one of {_VALID_MODALITIES}, got '{modality}'")
|
| 118 |
+
self._modality = modality
|
| 119 |
+
|
| 120 |
+
vision_cfg = config.vision_config
|
| 121 |
+
if not isinstance(vision_cfg, Qwen3VLVisionConfig):
|
| 122 |
+
d = vision_cfg.to_dict() if hasattr(vision_cfg, "to_dict") else dict(vision_cfg)
|
| 123 |
+
d.pop("model_type", None)
|
| 124 |
+
d.pop("transformers_version", None)
|
| 125 |
+
vision_cfg = Qwen3VLVisionConfig(**d)
|
| 126 |
+
vision_cfg.deepstack_visual_indexes = []
|
| 127 |
+
|
| 128 |
+
spatial_merge_size = getattr(vision_cfg, "spatial_merge_size", 2)
|
| 129 |
+
self._spatial_merge_size = spatial_merge_size
|
| 130 |
+
self._vision_hidden_size = vision_cfg.hidden_size
|
| 131 |
+
|
| 132 |
+
text_cfg = config.text_config
|
| 133 |
+
txt_dict = text_cfg.to_dict() if hasattr(text_cfg, "to_dict") else text_cfg
|
| 134 |
+
if not isinstance(text_cfg, LlamaConfig):
|
| 135 |
+
text_cfg = LlamaConfig(**txt_dict)
|
| 136 |
+
text_hidden = text_cfg.hidden_size
|
| 137 |
+
|
| 138 |
+
if modality not in ("audio", "text"):
|
| 139 |
+
self.vision_tower = Qwen3VLVisionModel(vision_cfg)
|
| 140 |
+
self.vision_tower.merger = nn.Identity()
|
| 141 |
+
self.vision_tower.deepstack_merger_list = nn.ModuleList()
|
| 142 |
+
self.vision_tower.deepstack_visual_indexes = []
|
| 143 |
+
self.mergers = nn.ModuleDict({
|
| 144 |
+
_key(t): PretrainedMerger(vision_cfg.hidden_size, text_hidden, spatial_merge_size)
|
| 145 |
+
for t in config.task_names
|
| 146 |
+
})
|
| 147 |
+
|
| 148 |
+
self.language_model = LlamaModel(text_cfg)
|
| 149 |
+
for layer in self.language_model.layers:
|
| 150 |
+
layer.self_attn.is_causal = False
|
| 151 |
+
|
| 152 |
+
self.multi_modal_projector = nn.Identity()
|
| 153 |
+
self.lm_head = nn.Identity()
|
| 154 |
+
|
| 155 |
+
if modality not in ("vision", "text"):
|
| 156 |
+
aud_cfg = config.audio_config
|
| 157 |
+
aud_dict = aud_cfg.to_dict() if hasattr(aud_cfg, "to_dict") else aud_cfg
|
| 158 |
+
audio_encoder_config = Qwen2_5OmniAudioEncoderConfig(**aud_dict)
|
| 159 |
+
self.audio_tower = Qwen2_5OmniAudioEncoder(audio_encoder_config)
|
| 160 |
+
self.audio_tower.proj = nn.Identity() # fused into audio_projector(s)
|
| 161 |
+
output_dim = aud_dict.get('d_model', 1280) # fused: audio_projector(s) now take d_model
|
| 162 |
+
self.audio_projectors = nn.ModuleDict({
|
| 163 |
+
_key(t): nn.Linear(output_dim, text_hidden) for t in config.task_names
|
| 164 |
+
})
|
| 165 |
+
|
| 166 |
+
ignore = []
|
| 167 |
+
if modality in ("audio", "text"):
|
| 168 |
+
ignore.extend([r"^vision_tower\.", r"^mergers\."])
|
| 169 |
+
if modality in ("vision", "text"):
|
| 170 |
+
ignore.extend([r"^audio_tower\.", r"^audio_projectors\."])
|
| 171 |
+
if ignore:
|
| 172 |
+
self._keys_to_ignore_on_load_unexpected = ignore
|
| 173 |
+
|
| 174 |
+
n_special = len(config.special_token_ids)
|
| 175 |
+
self.task_token_embeddings = nn.ParameterDict({
|
| 176 |
+
_key(t): nn.Parameter(torch.zeros(n_special, text_hidden))
|
| 177 |
+
for t in config.task_names
|
| 178 |
+
})
|
| 179 |
+
|
| 180 |
+
self._active_task_key = _key(config.task_names[0])
|
| 181 |
+
self._special_token_ids = config.special_token_ids
|
| 182 |
+
self.post_init()
|
| 183 |
+
|
| 184 |
+
@property
|
| 185 |
+
def modality(self) -> str:
|
| 186 |
+
return self._modality
|
| 187 |
+
|
| 188 |
+
def set_task(self, task):
|
| 189 |
+
k = _key(task)
|
| 190 |
+
self._active_task_key = k
|
| 191 |
+
with torch.no_grad():
|
| 192 |
+
w = self.language_model.embed_tokens.weight.data
|
| 193 |
+
te = self.task_token_embeddings[k]
|
| 194 |
+
for i, tid in enumerate(self._special_token_ids):
|
| 195 |
+
w[tid] = te[i]
|
| 196 |
+
|
| 197 |
+
def get_input_embeddings(self):
|
| 198 |
+
return self.language_model.embed_tokens
|
| 199 |
+
|
| 200 |
+
def set_input_embeddings(self, value):
|
| 201 |
+
self.language_model.embed_tokens = value
|
| 202 |
+
|
| 203 |
+
def get_output_embeddings(self):
|
| 204 |
+
return None
|
| 205 |
+
|
| 206 |
+
def get_image_features(self, pixel_values, image_grid_thw, num_image_tokens=None):
|
| 207 |
+
if self._modality in ("audio", "text"):
|
| 208 |
+
raise ValueError(
|
| 209 |
+
f"Vision inputs are not available in {self._modality}-only mode. "
|
| 210 |
+
"Load with modality='omni' or modality='vision'."
|
| 211 |
+
)
|
| 212 |
+
|
| 213 |
+
out = self.vision_tower(hidden_states=pixel_values, grid_thw=image_grid_thw)
|
| 214 |
+
raw = out[0] if isinstance(out, tuple) else getattr(out, "last_hidden_state", out[0])
|
| 215 |
+
merged = self.mergers[self._active_task_key](raw)
|
| 216 |
+
|
| 217 |
+
merge = self._spatial_merge_size
|
| 218 |
+
sizes = []
|
| 219 |
+
for i in range(image_grid_thw.shape[0]):
|
| 220 |
+
t, h, w = image_grid_thw[i].tolist()
|
| 221 |
+
sizes.append(int(t) * (int(h) // merge) * (int(w) // merge))
|
| 222 |
+
|
| 223 |
+
# Default: return the un-padded per-image feature slices. Their
|
| 224 |
+
# concatenation has exactly sum(sizes) rows == number of <image>
|
| 225 |
+
# placeholder tokens in input_ids, which is what masked_scatter
|
| 226 |
+
# consumes. Padding is only meaningful when callers want a square
|
| 227 |
+
# [N, max_tok, dim] block (e.g. multi-sample batched forward where
|
| 228 |
+
# each row owns its own image), and that path passes
|
| 229 |
+
# num_image_tokens explicitly to opt in.
|
| 230 |
+
dim = merged.shape[-1]
|
| 231 |
+
features, offset = [], 0
|
| 232 |
+
if num_image_tokens is not None:
|
| 233 |
+
max_tok = num_image_tokens
|
| 234 |
+
for n in sizes:
|
| 235 |
+
feat = merged[offset:offset + n]
|
| 236 |
+
if n < max_tok:
|
| 237 |
+
feat = torch.cat([feat, feat.new_zeros(max_tok - n, dim)], dim=0)
|
| 238 |
+
features.append(feat)
|
| 239 |
+
offset += n
|
| 240 |
+
else:
|
| 241 |
+
for n in sizes:
|
| 242 |
+
features.append(merged[offset:offset + n])
|
| 243 |
+
offset += n
|
| 244 |
+
return features
|
| 245 |
+
|
| 246 |
+
def get_audio_features(self, input_features, feature_attention_mask=None):
|
| 247 |
+
if self._modality in ("vision", "text"):
|
| 248 |
+
raise ValueError(
|
| 249 |
+
f"Audio inputs are not available in {self._modality}-only mode. "
|
| 250 |
+
"Load with modality='omni' or modality='audio'."
|
| 251 |
+
)
|
| 252 |
+
|
| 253 |
+
batch_size = input_features.shape[0]
|
| 254 |
+
if batch_size > 1:
|
| 255 |
+
# Serialize per-sample so the packed-frames GEMM shape stays invariant
|
| 256 |
+
# across batch sizes. Makes batched audio bit-exact to B=1 in bf16,
|
| 257 |
+
# and is substantially faster for B>=16 because B=1 hits a
|
| 258 |
+
# well-optimized kernel while the packed-B=N path thrashes on a
|
| 259 |
+
# (total_frames)^2 sdpa matrix.
|
| 260 |
+
outs = [
|
| 261 |
+
self.get_audio_features(
|
| 262 |
+
input_features[i : i + 1],
|
| 263 |
+
feature_attention_mask[i : i + 1] if feature_attention_mask is not None else None,
|
| 264 |
+
)
|
| 265 |
+
for i in range(batch_size)
|
| 266 |
+
]
|
| 267 |
+
return torch.cat(outs, dim=0)
|
| 268 |
+
if feature_attention_mask is not None:
|
| 269 |
+
feature_lens = feature_attention_mask.sum(-1).long()
|
| 270 |
+
packed = input_features.permute(0, 2, 1)[feature_attention_mask.bool()].permute(1, 0)
|
| 271 |
+
else:
|
| 272 |
+
feature_lens = torch.full(
|
| 273 |
+
(batch_size,), input_features.shape[2],
|
| 274 |
+
device=input_features.device, dtype=torch.long,
|
| 275 |
+
)
|
| 276 |
+
packed = input_features.transpose(1, 2).reshape(-1, input_features.shape[1]).T
|
| 277 |
+
aftercnn_lens, _ = self.audio_tower._get_feat_extract_output_lengths(feature_lens)
|
| 278 |
+
audio_output = self.audio_tower(
|
| 279 |
+
packed, feature_lens=feature_lens, aftercnn_lens=aftercnn_lens,
|
| 280 |
+
)
|
| 281 |
+
return self.audio_projectors[self._active_task_key](audio_output.last_hidden_state)
|
| 282 |
+
|
| 283 |
+
def forward(
|
| 284 |
+
self,
|
| 285 |
+
input_ids=None,
|
| 286 |
+
pixel_values=None,
|
| 287 |
+
attention_mask=None,
|
| 288 |
+
position_ids=None,
|
| 289 |
+
past_key_values=None,
|
| 290 |
+
inputs_embeds=None,
|
| 291 |
+
input_features=None,
|
| 292 |
+
feature_attention_mask=None,
|
| 293 |
+
cache_position=None,
|
| 294 |
+
output_hidden_states=None,
|
| 295 |
+
**kwargs,
|
| 296 |
+
):
|
| 297 |
+
image_grid_thw = kwargs.pop("image_grid_thw", None)
|
| 298 |
+
num_image_tokens = kwargs.pop("num_image_tokens", None)
|
| 299 |
+
pixel_values_videos = kwargs.pop("pixel_values_videos", None)
|
| 300 |
+
video_grid_thw = kwargs.pop("video_grid_thw", None)
|
| 301 |
+
num_video_tokens = kwargs.pop("num_video_tokens", None)
|
| 302 |
+
kwargs.pop("spatial_shapes", None)
|
| 303 |
+
kwargs.pop("pixel_attention_mask", None)
|
| 304 |
+
|
| 305 |
+
if pixel_values is not None and self._modality in ("audio", "text"):
|
| 306 |
+
raise ValueError(
|
| 307 |
+
f"Vision inputs are not available in {self._modality}-only mode. "
|
| 308 |
+
"Load with modality='omni' or modality='vision'."
|
| 309 |
+
)
|
| 310 |
+
if input_features is not None and self._modality in ("vision", "text"):
|
| 311 |
+
raise ValueError(
|
| 312 |
+
f"Audio inputs are not available in {self._modality}-only mode. "
|
| 313 |
+
"Load with modality='omni' or modality='audio'."
|
| 314 |
+
)
|
| 315 |
+
|
| 316 |
+
if (input_ids is None) ^ (inputs_embeds is not None):
|
| 317 |
+
raise ValueError("You must specify exactly one of input_ids or inputs_embeds")
|
| 318 |
+
|
| 319 |
+
if inputs_embeds is None:
|
| 320 |
+
inputs_embeds = self.get_input_embeddings()(input_ids)
|
| 321 |
+
|
| 322 |
+
# Image and video both use config.image_token_index (the processor
|
| 323 |
+
# remaps <|video_pad|> to <image>). When a single forward pass mixes
|
| 324 |
+
# both modalities, the mask matches both sets of placeholders, so we
|
| 325 |
+
# build one combined source with image features first then video
|
| 326 |
+
# features, matching the order of placeholders in input_ids.
|
| 327 |
+
all_feats = []
|
| 328 |
+
if pixel_values is not None and image_grid_thw is not None:
|
| 329 |
+
all_feats.extend(self.get_image_features(pixel_values, image_grid_thw, num_image_tokens))
|
| 330 |
+
if pixel_values_videos is not None and video_grid_thw is not None:
|
| 331 |
+
all_feats.extend(self.get_image_features(pixel_values_videos, video_grid_thw, num_video_tokens))
|
| 332 |
+
if all_feats:
|
| 333 |
+
feats = torch.cat(all_feats, dim=0).to(inputs_embeds.device, inputs_embeds.dtype)
|
| 334 |
+
mask = (input_ids == self.config.image_token_index).unsqueeze(-1).expand_as(inputs_embeds)
|
| 335 |
+
inputs_embeds = inputs_embeds.masked_scatter(mask, feats)
|
| 336 |
+
|
| 337 |
+
if input_features is not None:
|
| 338 |
+
aud = self.get_audio_features(input_features, feature_attention_mask)
|
| 339 |
+
aud_flat = aud.reshape(-1, aud.shape[-1]).to(inputs_embeds.device, inputs_embeds.dtype)
|
| 340 |
+
mask = (input_ids == self.config.audio_token_id).unsqueeze(-1).expand_as(inputs_embeds)
|
| 341 |
+
inputs_embeds = inputs_embeds.masked_scatter(mask, aud_flat)
|
| 342 |
+
|
| 343 |
+
if attention_mask is not None and attention_mask.dim() == 2:
|
| 344 |
+
dtype = inputs_embeds.dtype
|
| 345 |
+
seq_len = inputs_embeds.shape[1]
|
| 346 |
+
bidi = attention_mask[:, None, None, :].to(dtype=dtype)
|
| 347 |
+
bidi = (1.0 - bidi) * torch.finfo(dtype).min
|
| 348 |
+
attention_mask = bidi.expand(-1, -1, seq_len, -1)
|
| 349 |
+
|
| 350 |
+
out = self.language_model(
|
| 351 |
+
attention_mask=attention_mask,
|
| 352 |
+
position_ids=position_ids,
|
| 353 |
+
past_key_values=past_key_values,
|
| 354 |
+
inputs_embeds=inputs_embeds,
|
| 355 |
+
cache_position=cache_position,
|
| 356 |
+
output_hidden_states=output_hidden_states,
|
| 357 |
+
)
|
| 358 |
+
|
| 359 |
+
return BaseModelOutputWithPast(
|
| 360 |
+
last_hidden_state=self.lm_head(out[0]),
|
| 361 |
+
past_key_values=out.past_key_values,
|
| 362 |
+
hidden_states=out.hidden_states,
|
| 363 |
+
attentions=out.attentions,
|
| 364 |
+
)
|
| 365 |
+
|
| 366 |
+
|
| 367 |
+
class JinaEmbeddingsV5OmniModel(PeftMixedModel):
|
| 368 |
+
config_class = JinaEmbeddingsV5OmniConfig
|
| 369 |
+
|
| 370 |
+
@classmethod
|
| 371 |
+
def register_for_auto_class(cls, auto_class="AutoModel"):
|
| 372 |
+
return PreTrainedModel.register_for_auto_class.__func__(cls, auto_class)
|
| 373 |
+
|
| 374 |
+
@classmethod
|
| 375 |
+
def from_pretrained(cls, pretrained_model_name_or_path, *args, **kwargs):
|
| 376 |
+
modality = kwargs.pop("modality", None)
|
| 377 |
+
task_kwarg = kwargs.pop("task", None)
|
| 378 |
+
config = kwargs.pop("config", None)
|
| 379 |
+
if config is None:
|
| 380 |
+
config = JinaEmbeddingsV5OmniConfig.from_pretrained(pretrained_model_name_or_path)
|
| 381 |
+
if modality is not None:
|
| 382 |
+
config.modality = modality
|
| 383 |
+
elif not hasattr(config, "modality") or config.modality is None:
|
| 384 |
+
config.modality = "omni"
|
| 385 |
+
|
| 386 |
+
default_dtype = getattr(config, "torch_dtype", None) or torch.float32
|
| 387 |
+
base_model = JinaEmbeddingsV5OmniBase.from_pretrained(
|
| 388 |
+
pretrained_model_name_or_path,
|
| 389 |
+
config=config,
|
| 390 |
+
torch_dtype=kwargs.pop("torch_dtype", kwargs.pop("dtype", default_dtype)),
|
| 391 |
+
)
|
| 392 |
+
|
| 393 |
+
if os.path.isdir(pretrained_model_name_or_path):
|
| 394 |
+
adapters_dir = os.path.join(pretrained_model_name_or_path, "adapters")
|
| 395 |
+
else:
|
| 396 |
+
cache = snapshot_download(
|
| 397 |
+
repo_id=pretrained_model_name_or_path,
|
| 398 |
+
allow_patterns=["adapters/*"],
|
| 399 |
+
)
|
| 400 |
+
adapters_dir = os.path.join(cache, "adapters")
|
| 401 |
+
|
| 402 |
+
adapter_paths = {
|
| 403 |
+
name: os.path.join(adapters_dir, name) for name in config.task_names
|
| 404 |
+
}
|
| 405 |
+
|
| 406 |
+
peft_config = PeftConfig.from_pretrained(adapter_paths["retrieval"], **kwargs)
|
| 407 |
+
model = cls(base_model, peft_config, adapter_name="retrieval")
|
| 408 |
+
model._pretrained_path = pretrained_model_name_or_path
|
| 409 |
+
for name in config.task_names:
|
| 410 |
+
model.load_adapter(adapter_paths[name], adapter_name=name, **kwargs)
|
| 411 |
+
|
| 412 |
+
model.tokenizer = AutoTokenizer.from_pretrained(
|
| 413 |
+
pretrained_model_name_or_path, trust_remote_code=True,
|
| 414 |
+
)
|
| 415 |
+
# Task precedence: kwarg > config.task (hf_overrides path) > env var > default.
|
| 416 |
+
task = task_kwarg
|
| 417 |
+
if task is None:
|
| 418 |
+
task = getattr(config, "task", None)
|
| 419 |
+
if task is None:
|
| 420 |
+
task = os.environ.get("JINA_V5_TASK")
|
| 421 |
+
if task is None:
|
| 422 |
+
task = config.task_names[0]
|
| 423 |
+
if task not in config.task_names:
|
| 424 |
+
raise ValueError(
|
| 425 |
+
f"task must be one of {config.task_names}, got '{task}'"
|
| 426 |
+
)
|
| 427 |
+
model.set_adapter(task)
|
| 428 |
+
return model
|
| 429 |
+
|
| 430 |
+
@property
|
| 431 |
+
def modality(self) -> str:
|
| 432 |
+
return self.base_model.model.modality
|
| 433 |
+
|
| 434 |
+
def set_adapter(self, adapters):
|
| 435 |
+
super().set_adapter(adapters)
|
| 436 |
+
task = adapters[0] if isinstance(adapters, list) else adapters
|
| 437 |
+
self.base_model.model.set_task(task)
|
| 438 |
+
|
| 439 |
+
def encode(
|
| 440 |
+
self,
|
| 441 |
+
texts: List[str],
|
| 442 |
+
task: str,
|
| 443 |
+
prompt_name: Optional[str] = "document",
|
| 444 |
+
truncate_dim: Optional[int] = None,
|
| 445 |
+
max_length: Optional[int] = None,
|
| 446 |
+
) -> torch.Tensor:
|
| 447 |
+
cfg = self.base_model.model.config
|
| 448 |
+
if task not in cfg.task_names:
|
| 449 |
+
raise ValueError(f"Unknown task: {task}")
|
| 450 |
+
if prompt_name is None:
|
| 451 |
+
prompt_name = "document"
|
| 452 |
+
if prompt_name not in {"query", "document"}:
|
| 453 |
+
raise ValueError(f"Unknown prompt_name: {prompt_name}")
|
| 454 |
+
|
| 455 |
+
prefix = "Query: " if prompt_name == "query" else "Document: "
|
| 456 |
+
inputs = [f"{prefix}{t}" for t in texts]
|
| 457 |
+
|
| 458 |
+
max_length = max_length or cfg.text_config.max_position_embeddings
|
| 459 |
+
batch = self.tokenizer(
|
| 460 |
+
inputs, return_tensors="pt", padding=True, truncation=True, max_length=max_length,
|
| 461 |
+
)
|
| 462 |
+
device = next(self.parameters()).device
|
| 463 |
+
batch = {k: v.to(device) for k, v in batch.items()}
|
| 464 |
+
self.set_adapter([task])
|
| 465 |
+
self.eval()
|
| 466 |
+
with torch.no_grad():
|
| 467 |
+
hidden = self(**batch).last_hidden_state
|
| 468 |
+
mask = batch.get("attention_mask")
|
| 469 |
+
if mask is None:
|
| 470 |
+
pooled = hidden[:, -1]
|
| 471 |
+
else:
|
| 472 |
+
seq_lens = mask.sum(dim=1) - 1
|
| 473 |
+
pooled = hidden[torch.arange(hidden.shape[0], device=hidden.device), seq_lens]
|
| 474 |
+
if truncate_dim is not None:
|
| 475 |
+
pooled = pooled[:, :truncate_dim]
|
| 476 |
+
return F.normalize(pooled, p=2, dim=-1)
|
| 477 |
+
|
| 478 |
+
def embed(self, truncate_dim: Optional[int] = None, **inputs):
|
| 479 |
+
"""Encode processor outputs into L2-normalized last-token embeddings.
|
| 480 |
+
|
| 481 |
+
Matryoshka: pass `truncate_dim=N` to get an N-dim unit-norm vector
|
| 482 |
+
(truncation is applied before L2-normalization).
|
| 483 |
+
"""
|
| 484 |
+
attention_mask = inputs.get("attention_mask", None)
|
| 485 |
+
self.eval()
|
| 486 |
+
with torch.no_grad():
|
| 487 |
+
out = self(**inputs)
|
| 488 |
+
hidden = out.last_hidden_state
|
| 489 |
+
if attention_mask is not None and attention_mask.dim() == 2:
|
| 490 |
+
idx = attention_mask.sum(dim=1) - 1
|
| 491 |
+
else:
|
| 492 |
+
idx = torch.full(
|
| 493 |
+
(hidden.shape[0],), hidden.shape[1] - 1,
|
| 494 |
+
device=hidden.device, dtype=torch.long,
|
| 495 |
+
)
|
| 496 |
+
pooled = hidden[torch.arange(hidden.shape[0], device=hidden.device), idx]
|
| 497 |
+
if truncate_dim is not None:
|
| 498 |
+
pooled = pooled[:, :truncate_dim]
|
| 499 |
+
return torch.nn.functional.normalize(pooled, dim=-1)
|
| 500 |
+
|
| 501 |
+
|
| 502 |
+
|
| 503 |
+
# ---------------------------------------------------------------------------
|
| 504 |
+
# vLLM registration (side-effect on module import).
|
| 505 |
+
#
|
| 506 |
+
# Triggered via config.json "auto_map.AutoConfig" -> this module.
|
| 507 |
+
# HF / sentence-transformers path unaffected: any failure is silently swallowed
|
| 508 |
+
# so that pure transformers users never see a vLLM error.
|
| 509 |
+
# ---------------------------------------------------------------------------
|
| 510 |
+
|
| 511 |
+
def _register_vllm() -> None:
|
| 512 |
+
# All vLLM references are resolved via importlib so transformers'
|
| 513 |
+
# static check_imports does NOT flag vllm as a required dependency.
|
| 514 |
+
# Pure-HF / sentence-transformers usage is unaffected.
|
| 515 |
+
#
|
| 516 |
+
# When loaded via transformers' `trust_remote_code=True`, only the
|
| 517 |
+
# modeling_*.py referenced in auto_map is fetched into the
|
| 518 |
+
# transformers_modules cache — sibling vLLM adapter files are NOT.
|
| 519 |
+
# We pull them from HF Hub before registering; otherwise vLLM falls
|
| 520 |
+
# back to its transformers backend (wrong attention semantics) and
|
| 521 |
+
# multi-request batches collapse.
|
| 522 |
+
import importlib.util as _iu
|
| 523 |
+
if _iu.find_spec("vllm") is None:
|
| 524 |
+
return
|
| 525 |
+
try:
|
| 526 |
+
import os
|
| 527 |
+
import sys
|
| 528 |
+
import importlib
|
| 529 |
+
import inspect
|
| 530 |
+
import shutil
|
| 531 |
+
|
| 532 |
+
pkg = __package__ or ""
|
| 533 |
+
current_dir = os.path.dirname(os.path.abspath(__file__))
|
| 534 |
+
siblings = ("vllm_llava_eurobert_audio", "vllm_jina_v5_omni")
|
| 535 |
+
|
| 536 |
+
for sibling_name in siblings:
|
| 537 |
+
sibling_path = os.path.join(current_dir, sibling_name + ".py")
|
| 538 |
+
if os.path.exists(sibling_path):
|
| 539 |
+
continue
|
| 540 |
+
parts = pkg.split(".")
|
| 541 |
+
if len(parts) < 4 or parts[0] != "transformers_modules":
|
| 542 |
+
continue
|
| 543 |
+
from huggingface_hub import hf_hub_download
|
| 544 |
+
repo_name = parts[2].replace("_hyphen_", "-").replace("_dot_", ".")
|
| 545 |
+
repo_id = f"{parts[1]}/{repo_name}"
|
| 546 |
+
downloaded = hf_hub_download(
|
| 547 |
+
repo_id=repo_id,
|
| 548 |
+
filename=sibling_name + ".py",
|
| 549 |
+
revision=parts[3],
|
| 550 |
+
)
|
| 551 |
+
shutil.copy(downloaded, sibling_path)
|
| 552 |
+
|
| 553 |
+
os.environ.setdefault("VLLM_ENABLE_V1_MULTIPROCESSING", "0")
|
| 554 |
+
|
| 555 |
+
_kvc = importlib.import_module("vllm.v1.core.kv_cache_coordinator")
|
| 556 |
+
_orig = _kvc.get_kv_cache_coordinator
|
| 557 |
+
_NoPrefix = _kvc.KVCacheCoordinatorNoPrefixCache
|
| 558 |
+
|
| 559 |
+
_orig_sig = inspect.signature(_orig)
|
| 560 |
+
_noprefix_sig = inspect.signature(_NoPrefix)
|
| 561 |
+
|
| 562 |
+
def _patched(kv_cache_config, max_model_len, *args, **kwargs):
|
| 563 |
+
if len(kv_cache_config.kv_cache_groups) == 0:
|
| 564 |
+
bound = _orig_sig.bind(kv_cache_config, max_model_len, *args, **kwargs)
|
| 565 |
+
return _NoPrefix(**{
|
| 566 |
+
name: bound.arguments[name]
|
| 567 |
+
for name in _noprefix_sig.parameters
|
| 568 |
+
if name in bound.arguments
|
| 569 |
+
})
|
| 570 |
+
return _orig(kv_cache_config, max_model_len, *args, **kwargs)
|
| 571 |
+
|
| 572 |
+
_kvc.get_kv_cache_coordinator = _patched
|
| 573 |
+
|
| 574 |
+
# Make sibling-dir importable from a fresh subprocess too — vLLM's
|
| 575 |
+
# inspect_model_cls runs in a child Python process that doesn't
|
| 576 |
+
# inherit our sys.modules. Without this on PYTHONPATH the
|
| 577 |
+
# string-spec model registration below can't be resolved.
|
| 578 |
+
if current_dir not in sys.path:
|
| 579 |
+
sys.path.insert(0, current_dir)
|
| 580 |
+
existing = os.environ.get("PYTHONPATH", "")
|
| 581 |
+
if current_dir not in existing.split(os.pathsep):
|
| 582 |
+
os.environ["PYTHONPATH"] = (
|
| 583 |
+
current_dir if not existing else current_dir + os.pathsep + existing
|
| 584 |
+
)
|
| 585 |
+
|
| 586 |
+
if pkg:
|
| 587 |
+
_lla = importlib.import_module(".vllm_llava_eurobert_audio", package=pkg)
|
| 588 |
+
_omni = importlib.import_module(".vllm_jina_v5_omni", package=pkg)
|
| 589 |
+
else:
|
| 590 |
+
_lla = importlib.import_module("vllm_llava_eurobert_audio")
|
| 591 |
+
_omni = importlib.import_module("vllm_jina_v5_omni")
|
| 592 |
+
_ = _lla.LlavaEuroBertAudioForVLLMEmbedding # keep reference
|
| 593 |
+
|
| 594 |
+
ModelRegistry = importlib.import_module(
|
| 595 |
+
"vllm.model_executor.models"
|
| 596 |
+
).ModelRegistry
|
| 597 |
+
# String spec ("module:Class") — survives vLLM's cloudpickle-into-
|
| 598 |
+
# subprocess flow because the child re-imports by name. Passing the
|
| 599 |
+
# class object directly registers __module__ as the qualified
|
| 600 |
+
# transformers_modules.jinaai.<...> path, which the subprocess
|
| 601 |
+
# can't resolve without HF's dynamic-module setup.
|
| 602 |
+
ModelRegistry.register_model(
|
| 603 |
+
"JinaEmbeddingsV5OmniModel",
|
| 604 |
+
"vllm_jina_v5_omni:JinaV5OmniForVLLMEmbedding",
|
| 605 |
+
)
|
| 606 |
+
except Exception as e:
|
| 607 |
+
import warnings
|
| 608 |
+
warnings.warn(
|
| 609 |
+
f"jina-embeddings-v5-omni base: vLLM registration failed "
|
| 610 |
+
f"({type(e).__name__}: {e}); embeddings will fall back to "
|
| 611 |
+
f"vLLM's generic transformers backend (wrong tensor layout).",
|
| 612 |
+
stacklevel=2,
|
| 613 |
+
)
|
| 614 |
+
|
| 615 |
+
|
| 616 |
+
_register_vllm()
|
modeling_llava_eurobert_audio.py
ADDED
|
@@ -0,0 +1,400 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
LlavaEuroBertAudioForEmbedding: Qwen3VL vision + Qwen2.5-Omni audio + EuroBERT text.
|
| 3 |
+
|
| 4 |
+
Architecture:
|
| 5 |
+
- Vision: Qwen3VLVisionModel (with RoPE, 3D Conv3d patch embed, all layers)
|
| 6 |
+
- Merger: PretrainedMerger (top-level, NOT inside vision_tower)
|
| 7 |
+
- Audio: Qwen2_5OmniAudioEncoder (Qwen2.5-Omni) + Linear projector
|
| 8 |
+
- Text: LlamaModel (EuroBERT, bidirectional)
|
| 9 |
+
- LM head: Identity (embedding model, no vocab projection)
|
| 10 |
+
|
| 11 |
+
Modality loading:
|
| 12 |
+
model = AutoModel.from_pretrained(path, trust_remote_code=True, modality="omni") # all components (default)
|
| 13 |
+
model = AutoModel.from_pretrained(path, trust_remote_code=True, modality="vision") # no audio tower/projector
|
| 14 |
+
model = AutoModel.from_pretrained(path, trust_remote_code=True, modality="audio") # no vision tower/merger
|
| 15 |
+
"""
|
| 16 |
+
|
| 17 |
+
from typing import List, Optional, Union
|
| 18 |
+
|
| 19 |
+
import torch
|
| 20 |
+
import torch.nn as nn
|
| 21 |
+
from transformers import LlamaConfig, PreTrainedModel, PretrainedConfig
|
| 22 |
+
from transformers.modeling_outputs import BaseModelOutputWithPast
|
| 23 |
+
from transformers.models.llama.modeling_llama import LlamaModel
|
| 24 |
+
from transformers.models.qwen3_vl.configuration_qwen3_vl import Qwen3VLVisionConfig
|
| 25 |
+
from transformers.models.qwen3_vl.modeling_qwen3_vl import Qwen3VLVisionModel
|
| 26 |
+
from transformers.models.qwen2_5_omni.configuration_qwen2_5_omni import Qwen2_5OmniAudioEncoderConfig
|
| 27 |
+
from transformers.models.qwen2_5_omni.modeling_qwen2_5_omni import Qwen2_5OmniAudioEncoder
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
_VALID_MODALITIES = ("omni", "vision", "audio", "text")
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
class PretrainedMerger(nn.Module):
|
| 34 |
+
def __init__(self, hidden_size, out_hidden_size, spatial_merge_size=2):
|
| 35 |
+
super().__init__()
|
| 36 |
+
self.hidden_size = hidden_size * (spatial_merge_size**2)
|
| 37 |
+
self.norm = nn.LayerNorm(hidden_size, eps=1e-6)
|
| 38 |
+
self.linear_fc1 = nn.Linear(self.hidden_size, self.hidden_size)
|
| 39 |
+
self.act = nn.GELU()
|
| 40 |
+
self.linear_fc2 = nn.Linear(self.hidden_size, out_hidden_size)
|
| 41 |
+
|
| 42 |
+
def forward(self, x):
|
| 43 |
+
x = self.norm(x)
|
| 44 |
+
x = x.view(-1, self.hidden_size)
|
| 45 |
+
x = self.linear_fc2(self.act(self.linear_fc1(x)))
|
| 46 |
+
return x
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
class LlavaEuroBertAudioConfig(PretrainedConfig):
|
| 50 |
+
model_type = "llava_eurobert_audio"
|
| 51 |
+
|
| 52 |
+
def __init__(
|
| 53 |
+
self,
|
| 54 |
+
vision_config=None,
|
| 55 |
+
text_config=None,
|
| 56 |
+
audio_config=None,
|
| 57 |
+
image_token_index=None,
|
| 58 |
+
audio_token_id=None,
|
| 59 |
+
audio_start_token_id=None,
|
| 60 |
+
audio_end_token_id=None,
|
| 61 |
+
projector_hidden_act="gelu",
|
| 62 |
+
tie_word_embeddings=False,
|
| 63 |
+
modality="omni",
|
| 64 |
+
**kwargs,
|
| 65 |
+
):
|
| 66 |
+
if isinstance(vision_config, dict):
|
| 67 |
+
vision_config = PretrainedConfig(**vision_config)
|
| 68 |
+
self.vision_config = vision_config or PretrainedConfig()
|
| 69 |
+
if isinstance(text_config, dict):
|
| 70 |
+
text_config = PretrainedConfig(**text_config)
|
| 71 |
+
self.text_config = text_config or PretrainedConfig()
|
| 72 |
+
if isinstance(audio_config, dict):
|
| 73 |
+
audio_config = PretrainedConfig(**audio_config)
|
| 74 |
+
self.audio_config = audio_config or PretrainedConfig()
|
| 75 |
+
self.image_token_index = image_token_index
|
| 76 |
+
self.audio_token_id = audio_token_id
|
| 77 |
+
self.audio_start_token_id = audio_start_token_id
|
| 78 |
+
self.audio_end_token_id = audio_end_token_id
|
| 79 |
+
self.projector_hidden_act = projector_hidden_act
|
| 80 |
+
if modality not in _VALID_MODALITIES:
|
| 81 |
+
raise ValueError(f"modality must be one of {_VALID_MODALITIES}, got '{modality}'")
|
| 82 |
+
self.modality = modality
|
| 83 |
+
super().__init__(tie_word_embeddings=tie_word_embeddings, **kwargs)
|
| 84 |
+
|
| 85 |
+
def get_text_config(self, **kwargs):
|
| 86 |
+
return self.text_config
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
class LlavaEuroBertAudioForEmbedding(PreTrainedModel):
|
| 90 |
+
config_class = LlavaEuroBertAudioConfig
|
| 91 |
+
supports_gradient_checkpointing = True
|
| 92 |
+
_supports_sdpa = True
|
| 93 |
+
_supports_flash_attn_2 = True
|
| 94 |
+
_supports_attention_backend = True
|
| 95 |
+
_tied_weights_keys = []
|
| 96 |
+
_keys_to_ignore_on_load_missing = ["lm_head.weight"]
|
| 97 |
+
_keys_to_ignore_on_load_unexpected = []
|
| 98 |
+
|
| 99 |
+
def __init__(self, config: LlavaEuroBertAudioConfig):
|
| 100 |
+
super().__init__(config)
|
| 101 |
+
|
| 102 |
+
modality = getattr(config, "modality", "omni")
|
| 103 |
+
if modality not in _VALID_MODALITIES:
|
| 104 |
+
raise ValueError(f"modality must be one of {_VALID_MODALITIES}, got '{modality}'")
|
| 105 |
+
self._modality = modality
|
| 106 |
+
|
| 107 |
+
vision_cfg = config.vision_config
|
| 108 |
+
if not isinstance(vision_cfg, Qwen3VLVisionConfig):
|
| 109 |
+
if hasattr(vision_cfg, "to_dict"):
|
| 110 |
+
d = vision_cfg.to_dict()
|
| 111 |
+
else:
|
| 112 |
+
d = dict(vision_cfg)
|
| 113 |
+
d.pop("model_type", None)
|
| 114 |
+
d.pop("transformers_version", None)
|
| 115 |
+
vision_cfg = Qwen3VLVisionConfig(**d)
|
| 116 |
+
|
| 117 |
+
vision_cfg.deepstack_visual_indexes = []
|
| 118 |
+
spatial_merge_size = getattr(vision_cfg, "spatial_merge_size", 2)
|
| 119 |
+
|
| 120 |
+
text_cfg = config.text_config
|
| 121 |
+
if not isinstance(text_cfg, LlamaConfig):
|
| 122 |
+
txt_dict = text_cfg.to_dict() if hasattr(text_cfg, 'to_dict') else dict(text_cfg)
|
| 123 |
+
_saved_attn_impl = getattr(text_cfg, "_attn_implementation", None)
|
| 124 |
+
text_cfg = LlamaConfig(**txt_dict)
|
| 125 |
+
if _saved_attn_impl is not None:
|
| 126 |
+
text_cfg._attn_implementation = _saved_attn_impl
|
| 127 |
+
text_hidden = text_cfg.hidden_size
|
| 128 |
+
|
| 129 |
+
self._spatial_merge_size = spatial_merge_size
|
| 130 |
+
self._vision_hidden_size = getattr(vision_cfg, "hidden_size", 768)
|
| 131 |
+
|
| 132 |
+
if modality not in ("audio", "text"):
|
| 133 |
+
self.vision_tower = Qwen3VLVisionModel(vision_cfg)
|
| 134 |
+
self.vision_tower.merger = nn.Identity()
|
| 135 |
+
self.vision_tower.deepstack_merger_list = nn.ModuleList()
|
| 136 |
+
self.vision_tower.deepstack_visual_indexes = []
|
| 137 |
+
self.merger = PretrainedMerger(
|
| 138 |
+
vision_cfg.hidden_size, text_hidden, spatial_merge_size
|
| 139 |
+
)
|
| 140 |
+
|
| 141 |
+
self.multi_modal_projector = nn.Identity()
|
| 142 |
+
self.language_model = LlamaModel(text_cfg)
|
| 143 |
+
self.lm_head = nn.Identity()
|
| 144 |
+
|
| 145 |
+
for layer in self.language_model.layers:
|
| 146 |
+
layer.self_attn.is_causal = False
|
| 147 |
+
|
| 148 |
+
if modality not in ("vision", "text"):
|
| 149 |
+
aud_cfg = config.audio_config
|
| 150 |
+
aud_dict = aud_cfg.to_dict() if hasattr(aud_cfg, 'to_dict') else aud_cfg
|
| 151 |
+
audio_encoder_config = Qwen2_5OmniAudioEncoderConfig(**aud_dict)
|
| 152 |
+
self.audio_tower = Qwen2_5OmniAudioEncoder(audio_encoder_config)
|
| 153 |
+
output_dim = aud_dict.get('output_dim', 3584)
|
| 154 |
+
self.audio_projector = nn.Linear(output_dim, text_hidden)
|
| 155 |
+
|
| 156 |
+
ignore = []
|
| 157 |
+
if modality in ("audio", "text"):
|
| 158 |
+
ignore.extend([r"^vision_tower\.", r"^merger\."])
|
| 159 |
+
if modality in ("vision", "text"):
|
| 160 |
+
ignore.extend([r"^audio_tower\.", r"^audio_projector\."])
|
| 161 |
+
if ignore:
|
| 162 |
+
self._keys_to_ignore_on_load_unexpected = ignore
|
| 163 |
+
|
| 164 |
+
self.post_init()
|
| 165 |
+
|
| 166 |
+
@property
|
| 167 |
+
def modality(self) -> str:
|
| 168 |
+
return self._modality
|
| 169 |
+
|
| 170 |
+
def get_input_embeddings(self):
|
| 171 |
+
return self.language_model.embed_tokens
|
| 172 |
+
|
| 173 |
+
def set_input_embeddings(self, value):
|
| 174 |
+
self.language_model.embed_tokens = value
|
| 175 |
+
|
| 176 |
+
def get_output_embeddings(self):
|
| 177 |
+
return None
|
| 178 |
+
|
| 179 |
+
def get_image_features(
|
| 180 |
+
self,
|
| 181 |
+
pixel_values: torch.FloatTensor,
|
| 182 |
+
image_grid_thw: torch.LongTensor,
|
| 183 |
+
num_image_tokens: Optional[int] = None,
|
| 184 |
+
) -> List[torch.Tensor]:
|
| 185 |
+
if self._modality in ("audio", "text"):
|
| 186 |
+
raise ValueError(
|
| 187 |
+
f"Vision inputs are not available in {self._modality}-only mode. "
|
| 188 |
+
"Load with modality='omni' or modality='vision'."
|
| 189 |
+
)
|
| 190 |
+
|
| 191 |
+
vision_output = self.vision_tower(
|
| 192 |
+
hidden_states=pixel_values, grid_thw=image_grid_thw
|
| 193 |
+
)
|
| 194 |
+
if isinstance(vision_output, tuple):
|
| 195 |
+
raw_hidden = vision_output[0]
|
| 196 |
+
elif hasattr(vision_output, "pooler_output") and vision_output.pooler_output is not None:
|
| 197 |
+
raw_hidden = vision_output.pooler_output
|
| 198 |
+
else:
|
| 199 |
+
raw_hidden = vision_output[0]
|
| 200 |
+
|
| 201 |
+
image_features = self.merger(raw_hidden)
|
| 202 |
+
|
| 203 |
+
merge_sq = self._spatial_merge_size ** 2
|
| 204 |
+
split_sizes = (image_grid_thw.prod(-1) // merge_sq).tolist()
|
| 205 |
+
return list(torch.split(image_features, split_sizes))
|
| 206 |
+
|
| 207 |
+
def get_audio_features(
|
| 208 |
+
self,
|
| 209 |
+
input_features: torch.FloatTensor,
|
| 210 |
+
feature_attention_mask: Optional[torch.LongTensor] = None,
|
| 211 |
+
) -> torch.Tensor:
|
| 212 |
+
if self._modality in ("vision", "text"):
|
| 213 |
+
raise ValueError(
|
| 214 |
+
f"Audio inputs are not available in {self._modality}-only mode. "
|
| 215 |
+
"Load with modality='omni' or modality='audio'."
|
| 216 |
+
)
|
| 217 |
+
|
| 218 |
+
batch_size = input_features.shape[0]
|
| 219 |
+
if batch_size > 1:
|
| 220 |
+
# Serialize per-sample so the packed-frames GEMM shape stays invariant
|
| 221 |
+
# across batch sizes. Makes batched audio bit-exact to B=1 in bf16,
|
| 222 |
+
# and is substantially faster for B>=16 because B=1 hits a
|
| 223 |
+
# well-optimized kernel while the packed-B=N path thrashes on a
|
| 224 |
+
# (total_frames)^2 sdpa matrix.
|
| 225 |
+
outs = [
|
| 226 |
+
self.get_audio_features(
|
| 227 |
+
input_features[i : i + 1],
|
| 228 |
+
feature_attention_mask[i : i + 1] if feature_attention_mask is not None else None,
|
| 229 |
+
)
|
| 230 |
+
for i in range(batch_size)
|
| 231 |
+
]
|
| 232 |
+
return torch.cat(outs, dim=0)
|
| 233 |
+
if feature_attention_mask is not None:
|
| 234 |
+
feature_lens = feature_attention_mask.sum(-1).long()
|
| 235 |
+
packed = input_features.permute(0, 2, 1)[feature_attention_mask.bool()].permute(1, 0)
|
| 236 |
+
else:
|
| 237 |
+
feature_lens = torch.full(
|
| 238 |
+
(batch_size,), input_features.shape[2],
|
| 239 |
+
device=input_features.device, dtype=torch.long,
|
| 240 |
+
)
|
| 241 |
+
packed = input_features.transpose(1, 2).reshape(-1, input_features.shape[1]).T
|
| 242 |
+
aftercnn_lens, _ = self.audio_tower._get_feat_extract_output_lengths(feature_lens)
|
| 243 |
+
audio_output = self.audio_tower(
|
| 244 |
+
packed, feature_lens=feature_lens, aftercnn_lens=aftercnn_lens,
|
| 245 |
+
)
|
| 246 |
+
return self.audio_projector(audio_output.last_hidden_state)
|
| 247 |
+
|
| 248 |
+
def forward(
|
| 249 |
+
self,
|
| 250 |
+
input_ids: Optional[torch.LongTensor] = None,
|
| 251 |
+
pixel_values: Optional[torch.FloatTensor] = None,
|
| 252 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 253 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 254 |
+
past_key_values=None,
|
| 255 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 256 |
+
input_features: Optional[torch.FloatTensor] = None,
|
| 257 |
+
feature_attention_mask: Optional[torch.LongTensor] = None,
|
| 258 |
+
cache_position: Optional[torch.LongTensor] = None,
|
| 259 |
+
output_hidden_states: Optional[bool] = None,
|
| 260 |
+
**kwargs,
|
| 261 |
+
):
|
| 262 |
+
image_grid_thw = kwargs.pop("image_grid_thw", None)
|
| 263 |
+
num_image_tokens = kwargs.pop("num_image_tokens", None)
|
| 264 |
+
kwargs.pop("spatial_shapes", None)
|
| 265 |
+
kwargs.pop("pixel_attention_mask", None)
|
| 266 |
+
|
| 267 |
+
if pixel_values is not None and self._modality in ("audio", "text"):
|
| 268 |
+
raise ValueError(
|
| 269 |
+
f"Vision inputs are not available in {self._modality}-only mode. "
|
| 270 |
+
"Load with modality='omni' or modality='vision'."
|
| 271 |
+
)
|
| 272 |
+
if input_features is not None and self._modality in ("vision", "text"):
|
| 273 |
+
raise ValueError(
|
| 274 |
+
f"Audio inputs are not available in {self._modality}-only mode. "
|
| 275 |
+
"Load with modality='omni' or modality='audio'."
|
| 276 |
+
)
|
| 277 |
+
|
| 278 |
+
if (input_ids is None) ^ (inputs_embeds is not None):
|
| 279 |
+
raise ValueError(
|
| 280 |
+
"You must specify exactly one of input_ids or inputs_embeds"
|
| 281 |
+
)
|
| 282 |
+
|
| 283 |
+
if inputs_embeds is None:
|
| 284 |
+
inputs_embeds = self.get_input_embeddings()(input_ids)
|
| 285 |
+
|
| 286 |
+
if pixel_values is not None and image_grid_thw is not None:
|
| 287 |
+
image_features = self.get_image_features(
|
| 288 |
+
pixel_values=pixel_values,
|
| 289 |
+
image_grid_thw=image_grid_thw,
|
| 290 |
+
num_image_tokens=num_image_tokens,
|
| 291 |
+
)
|
| 292 |
+
image_features = torch.cat(image_features, dim=0).to(
|
| 293 |
+
inputs_embeds.device, inputs_embeds.dtype
|
| 294 |
+
)
|
| 295 |
+
special_image_mask = (
|
| 296 |
+
(input_ids == self.config.image_token_index)
|
| 297 |
+
.unsqueeze(-1)
|
| 298 |
+
.expand_as(inputs_embeds)
|
| 299 |
+
)
|
| 300 |
+
inputs_embeds = inputs_embeds.masked_scatter(
|
| 301 |
+
special_image_mask, image_features
|
| 302 |
+
)
|
| 303 |
+
|
| 304 |
+
if input_features is not None:
|
| 305 |
+
audio_embeds = self.get_audio_features(
|
| 306 |
+
input_features, feature_attention_mask
|
| 307 |
+
)
|
| 308 |
+
audio_embeds_flat = audio_embeds.reshape(
|
| 309 |
+
-1, audio_embeds.shape[-1]
|
| 310 |
+
).to(inputs_embeds.device, inputs_embeds.dtype)
|
| 311 |
+
audio_mask = (
|
| 312 |
+
(input_ids == self.config.audio_token_id)
|
| 313 |
+
.unsqueeze(-1)
|
| 314 |
+
.expand_as(inputs_embeds)
|
| 315 |
+
)
|
| 316 |
+
inputs_embeds = inputs_embeds.masked_scatter(
|
| 317 |
+
audio_mask, audio_embeds_flat
|
| 318 |
+
)
|
| 319 |
+
|
| 320 |
+
if attention_mask is not None and attention_mask.dim() == 2:
|
| 321 |
+
dtype = inputs_embeds.dtype
|
| 322 |
+
seq_len = inputs_embeds.shape[1]
|
| 323 |
+
bidi_mask = attention_mask[:, None, None, :].to(dtype=dtype)
|
| 324 |
+
bidi_mask = (1.0 - bidi_mask) * torch.finfo(dtype).min
|
| 325 |
+
attention_mask = bidi_mask.expand(-1, -1, seq_len, -1)
|
| 326 |
+
|
| 327 |
+
# vLLM's transformers backend passes `return_dict=False` + `attention_instances`.
|
| 328 |
+
# Force dict-style output internally, and forward remaining kwargs so the
|
| 329 |
+
# vllm attention hook receives its `attention_instances` dict.
|
| 330 |
+
kwargs.pop("return_dict", None)
|
| 331 |
+
outputs = self.language_model(
|
| 332 |
+
attention_mask=attention_mask,
|
| 333 |
+
position_ids=position_ids,
|
| 334 |
+
past_key_values=past_key_values,
|
| 335 |
+
inputs_embeds=inputs_embeds,
|
| 336 |
+
cache_position=cache_position,
|
| 337 |
+
output_hidden_states=output_hidden_states,
|
| 338 |
+
return_dict=True,
|
| 339 |
+
**kwargs,
|
| 340 |
+
)
|
| 341 |
+
|
| 342 |
+
hidden_states = outputs[0]
|
| 343 |
+
logits = self.lm_head(hidden_states)
|
| 344 |
+
|
| 345 |
+
return BaseModelOutputWithPast(
|
| 346 |
+
last_hidden_state=logits,
|
| 347 |
+
past_key_values=outputs.past_key_values,
|
| 348 |
+
hidden_states=outputs.hidden_states,
|
| 349 |
+
attentions=outputs.attentions,
|
| 350 |
+
)
|
| 351 |
+
|
| 352 |
+
|
| 353 |
+
def _register_vllm() -> None:
|
| 354 |
+
import importlib.util as _iu
|
| 355 |
+
if _iu.find_spec("vllm") is None:
|
| 356 |
+
return
|
| 357 |
+
try:
|
| 358 |
+
import os, sys, importlib, shutil
|
| 359 |
+
pkg = __package__ or ""
|
| 360 |
+
current_dir = os.path.dirname(os.path.abspath(__file__))
|
| 361 |
+
sibling_name = "vllm_llava_eurobert_audio"
|
| 362 |
+
sibling_path = os.path.join(current_dir, sibling_name + ".py")
|
| 363 |
+
if not os.path.exists(sibling_path):
|
| 364 |
+
parts = pkg.split(".")
|
| 365 |
+
if len(parts) >= 4 and parts[0] == "transformers_modules":
|
| 366 |
+
from huggingface_hub import hf_hub_download
|
| 367 |
+
repo_name = parts[2].replace("_hyphen_", "-").replace("_dot_", ".")
|
| 368 |
+
repo_id = f"{parts[1]}/{repo_name}"
|
| 369 |
+
downloaded = hf_hub_download(
|
| 370 |
+
repo_id=repo_id,
|
| 371 |
+
filename=sibling_name + ".py",
|
| 372 |
+
revision=parts[3],
|
| 373 |
+
)
|
| 374 |
+
shutil.copy(downloaded, sibling_path)
|
| 375 |
+
if current_dir not in sys.path:
|
| 376 |
+
sys.path.insert(0, current_dir)
|
| 377 |
+
existing = os.environ.get("PYTHONPATH", "")
|
| 378 |
+
if current_dir not in existing.split(os.pathsep):
|
| 379 |
+
os.environ["PYTHONPATH"] = (
|
| 380 |
+
current_dir if not existing else current_dir + os.pathsep + existing
|
| 381 |
+
)
|
| 382 |
+
if pkg:
|
| 383 |
+
_lla = importlib.import_module("." + sibling_name, package=pkg)
|
| 384 |
+
else:
|
| 385 |
+
_lla = importlib.import_module(sibling_name)
|
| 386 |
+
from vllm import ModelRegistry
|
| 387 |
+
ModelRegistry.register_model(
|
| 388 |
+
"LlavaEuroBertAudioForEmbedding",
|
| 389 |
+
_lla.LlavaEuroBertAudioForVLLMEmbedding,
|
| 390 |
+
)
|
| 391 |
+
except Exception as e:
|
| 392 |
+
import warnings
|
| 393 |
+
warnings.warn(
|
| 394 |
+
f"jina-embeddings-v5-omni nano: vLLM registration failed "
|
| 395 |
+
f"({type(e).__name__}: {e}); falling back to Transformers backend.",
|
| 396 |
+
stacklevel=2,
|
| 397 |
+
)
|
| 398 |
+
|
| 399 |
+
|
| 400 |
+
_register_vllm()
|
modules.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[
|
| 2 |
+
{
|
| 3 |
+
"idx": 0,
|
| 4 |
+
"name": "transformer",
|
| 5 |
+
"path": "",
|
| 6 |
+
"type": "custom_st.Transformer"
|
| 7 |
+
}
|
| 8 |
+
]
|
preprocessor_config.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"do_convert_rgb": true,
|
| 3 |
+
"do_normalize": true,
|
| 4 |
+
"do_rescale": true,
|
| 5 |
+
"do_resize": true,
|
| 6 |
+
"image_mean": [
|
| 7 |
+
0.5,
|
| 8 |
+
0.5,
|
| 9 |
+
0.5
|
| 10 |
+
],
|
| 11 |
+
"image_processor_type": "Qwen2VLImageProcessor",
|
| 12 |
+
"image_std": [
|
| 13 |
+
0.5,
|
| 14 |
+
0.5,
|
| 15 |
+
0.5
|
| 16 |
+
],
|
| 17 |
+
"merge_size": 2,
|
| 18 |
+
"patch_size": 16,
|
| 19 |
+
"resample": 3,
|
| 20 |
+
"rescale_factor": 0.00392156862745098,
|
| 21 |
+
"temporal_patch_size": 2,
|
| 22 |
+
"min_pixels": 262144,
|
| 23 |
+
"max_pixels": 1310720
|
| 24 |
+
}
|
processing_llava_eurobert.py
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Custom processor for jina-embeddings-v5-omni-nano.
|
| 2 |
+
|
| 3 |
+
Keeps Qwen2VL image/video preprocessing (pixel_values, pixel_values_videos,
|
| 4 |
+
image_grid_thw, video_grid_thw) but maps both media placeholders to nano's
|
| 5 |
+
<image> token instead of Qwen's <|image_pad|> / <|video_pad|>.
|
| 6 |
+
|
| 7 |
+
Qwen2VLProcessor expands self.image_token once per image_grid_thw entry and
|
| 8 |
+
self.video_token once per video_grid_thw entry. Overriding both to "<image>"
|
| 9 |
+
makes the super() call expand either modality into N consecutive <image>
|
| 10 |
+
tokens where N = prod(grid_thw) // merge_size**2.
|
| 11 |
+
"""
|
| 12 |
+
|
| 13 |
+
from transformers.models.qwen2_vl.processing_qwen2_vl import (
|
| 14 |
+
Qwen2VLProcessor,
|
| 15 |
+
)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class LlavaEuroBertProcessor(Qwen2VLProcessor):
|
| 19 |
+
|
| 20 |
+
def __init__(
|
| 21 |
+
self,
|
| 22 |
+
image_processor=None,
|
| 23 |
+
tokenizer=None,
|
| 24 |
+
video_processor=None,
|
| 25 |
+
chat_template=None,
|
| 26 |
+
**kwargs,
|
| 27 |
+
):
|
| 28 |
+
super().__init__(
|
| 29 |
+
image_processor=image_processor,
|
| 30 |
+
tokenizer=tokenizer,
|
| 31 |
+
video_processor=video_processor,
|
| 32 |
+
chat_template=chat_template,
|
| 33 |
+
**kwargs,
|
| 34 |
+
)
|
| 35 |
+
self.image_token = "<image>"
|
| 36 |
+
self.image_token_id = tokenizer.convert_tokens_to_ids(
|
| 37 |
+
self.image_token
|
| 38 |
+
)
|
| 39 |
+
self.video_token = "<image>"
|
| 40 |
+
self.video_token_id = self.image_token_id
|
| 41 |
+
|
| 42 |
+
def __call__(
|
| 43 |
+
self, images=None, text=None, videos=None, **kwargs
|
| 44 |
+
):
|
| 45 |
+
if text is not None:
|
| 46 |
+
if isinstance(text, str):
|
| 47 |
+
text = [text]
|
| 48 |
+
text = [
|
| 49 |
+
t.replace(
|
| 50 |
+
"<|vision_start|><|image_pad|><|vision_end|>",
|
| 51 |
+
"<image>",
|
| 52 |
+
)
|
| 53 |
+
.replace(
|
| 54 |
+
"<|vision_start|><|video_pad|><|vision_end|>",
|
| 55 |
+
"<image>",
|
| 56 |
+
)
|
| 57 |
+
.replace("<|image_pad|>", "<image>")
|
| 58 |
+
.replace("<|video_pad|>", "<image>")
|
| 59 |
+
.replace("<|vision_start|>", "")
|
| 60 |
+
.replace("<|vision_end|>", "")
|
| 61 |
+
for t in text
|
| 62 |
+
]
|
| 63 |
+
return super().__call__(
|
| 64 |
+
images=images, text=text, videos=videos, **kwargs
|
| 65 |
+
)
|
processor_config.json
ADDED
|
@@ -0,0 +1,68 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"processor_class": "LlavaEuroBertProcessor",
|
| 3 |
+
"auto_map": {
|
| 4 |
+
"AutoProcessor": "processing_llava_eurobert.LlavaEuroBertProcessor"
|
| 5 |
+
},
|
| 6 |
+
"image_processor": {
|
| 7 |
+
"image_processor_type": "Qwen2VLImageProcessorFast",
|
| 8 |
+
"do_convert_rgb": true,
|
| 9 |
+
"do_normalize": true,
|
| 10 |
+
"do_rescale": true,
|
| 11 |
+
"do_resize": true,
|
| 12 |
+
"image_mean": [
|
| 13 |
+
0.5,
|
| 14 |
+
0.5,
|
| 15 |
+
0.5
|
| 16 |
+
],
|
| 17 |
+
"image_std": [
|
| 18 |
+
0.5,
|
| 19 |
+
0.5,
|
| 20 |
+
0.5
|
| 21 |
+
],
|
| 22 |
+
"min_pixels": 262144,
|
| 23 |
+
"max_pixels": 1310720,
|
| 24 |
+
"size": {
|
| 25 |
+
"longest_edge": 16777216,
|
| 26 |
+
"shortest_edge": 65536
|
| 27 |
+
},
|
| 28 |
+
"merge_size": 2,
|
| 29 |
+
"patch_size": 16,
|
| 30 |
+
"resample": 3,
|
| 31 |
+
"rescale_factor": 0.00392156862745098,
|
| 32 |
+
"temporal_patch_size": 2
|
| 33 |
+
},
|
| 34 |
+
"video_processor": {
|
| 35 |
+
"video_processor_type": "Qwen3VLVideoProcessor",
|
| 36 |
+
"do_convert_rgb": true,
|
| 37 |
+
"do_normalize": true,
|
| 38 |
+
"do_rescale": true,
|
| 39 |
+
"do_resize": true,
|
| 40 |
+
"do_sample_frames": true,
|
| 41 |
+
"fps": 2,
|
| 42 |
+
"image_mean": [
|
| 43 |
+
0.5,
|
| 44 |
+
0.5,
|
| 45 |
+
0.5
|
| 46 |
+
],
|
| 47 |
+
"image_std": [
|
| 48 |
+
0.5,
|
| 49 |
+
0.5,
|
| 50 |
+
0.5
|
| 51 |
+
],
|
| 52 |
+
"max_frames": 768,
|
| 53 |
+
"min_frames": 4,
|
| 54 |
+
"merge_size": 2,
|
| 55 |
+
"patch_size": 16,
|
| 56 |
+
"resample": 3,
|
| 57 |
+
"rescale_factor": 0.00392156862745098,
|
| 58 |
+
"size": {
|
| 59 |
+
"longest_edge": 25165824,
|
| 60 |
+
"shortest_edge": 4096
|
| 61 |
+
},
|
| 62 |
+
"temporal_patch_size": 2
|
| 63 |
+
},
|
| 64 |
+
"image_token": "<image>",
|
| 65 |
+
"num_additional_image_tokens": 0,
|
| 66 |
+
"patch_size": null,
|
| 67 |
+
"vision_feature_select_strategy": null
|
| 68 |
+
}
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b8135ff0f019acbce7c4b93d1fb24cb8325b5fb0d76c57bbde8101a73cba7fa9
|
| 3 |
+
size 17211089
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"backend": "tokenizers",
|
| 3 |
+
"bos_token": "<|begin_of_text|>",
|
| 4 |
+
"clean_up_tokenization_spaces": true,
|
| 5 |
+
"eos_token": "<|end_of_text|>",
|
| 6 |
+
"is_local": false,
|
| 7 |
+
"mask_token": "<|mask|>",
|
| 8 |
+
"max_length": null,
|
| 9 |
+
"model_input_names": [
|
| 10 |
+
"input_ids",
|
| 11 |
+
"attention_mask"
|
| 12 |
+
],
|
| 13 |
+
"model_max_length": 1000000000000000019884624838656,
|
| 14 |
+
"pad_to_multiple_of": null,
|
| 15 |
+
"pad_token": "<|pad|>",
|
| 16 |
+
"pad_token_type_id": 0,
|
| 17 |
+
"padding_side": "right",
|
| 18 |
+
"processor_class": "LlavaEuroBertProcessor",
|
| 19 |
+
"tokenizer_class": "TokenizersBackend",
|
| 20 |
+
"auto_map": {
|
| 21 |
+
"AutoProcessor": "processing_llava_eurobert.LlavaEuroBertProcessor"
|
| 22 |
+
}
|
| 23 |
+
}
|
video_preprocessor_config.json
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"do_sample_frames": false,
|
| 3 |
+
"fps": 2,
|
| 4 |
+
"min_frames": 4,
|
| 5 |
+
"max_frames": 32,
|
| 6 |
+
"size": {
|
| 7 |
+
"longest_edge": 12845056,
|
| 8 |
+
"shortest_edge": 262144
|
| 9 |
+
},
|
| 10 |
+
"patch_size": 16,
|
| 11 |
+
"merge_size": 2,
|
| 12 |
+
"temporal_patch_size": 2,
|
| 13 |
+
"do_convert_rgb": true,
|
| 14 |
+
"do_normalize": true,
|
| 15 |
+
"do_rescale": true,
|
| 16 |
+
"do_resize": true,
|
| 17 |
+
"image_mean": [
|
| 18 |
+
0.5,
|
| 19 |
+
0.5,
|
| 20 |
+
0.5
|
| 21 |
+
],
|
| 22 |
+
"image_std": [
|
| 23 |
+
0.5,
|
| 24 |
+
0.5,
|
| 25 |
+
0.5
|
| 26 |
+
],
|
| 27 |
+
"rescale_factor": 0.00392156862745098,
|
| 28 |
+
"resample": 3
|
| 29 |
+
}
|
vllm_jina_v5_omni.py
ADDED
|
@@ -0,0 +1,175 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""vLLM implementation for jina-embeddings-v5-omni-nano / -small base models.
|
| 2 |
+
|
| 3 |
+
The base models expose:
|
| 4 |
+
- shared LM + vision + audio weights,
|
| 5 |
+
- a per-task LoRA adapter (in adapters/{task}/adapter_model.safetensors),
|
| 6 |
+
- a per-task PretrainedMerger (vision projection),
|
| 7 |
+
- a per-task audio_projector,
|
| 8 |
+
- per-task extra token embeddings applied to language_model.embed_tokens.
|
| 9 |
+
|
| 10 |
+
vLLM requires a concrete static model at load time, so we resolve the task from
|
| 11 |
+
the environment variable JINA_V5_TASK (default: retrieval). At load_weights time
|
| 12 |
+
we read the base safetensors + the selected adapter, merge LoRA into Q/K/V/O and
|
| 13 |
+
gate/up/down projections, rename the task-specific mergers/projectors/token
|
| 14 |
+
embeddings to their singular form, and stream the resulting state dict into the
|
| 15 |
+
existing LlavaEuroBertAudioForVLLMEmbedding weight loader — producing a forward
|
| 16 |
+
that is identical to the jinaai/jina-embeddings-v5-omni-nano-{task} variant.
|
| 17 |
+
|
| 18 |
+
One task per vLLM instance; spawn separate servers for multi-task serving.
|
| 19 |
+
"""
|
| 20 |
+
from __future__ import annotations
|
| 21 |
+
|
| 22 |
+
import json
|
| 23 |
+
import os
|
| 24 |
+
from pathlib import Path
|
| 25 |
+
from typing import Iterable
|
| 26 |
+
|
| 27 |
+
import torch
|
| 28 |
+
from safetensors import safe_open
|
| 29 |
+
|
| 30 |
+
try:
|
| 31 |
+
# Package import — works when HF dynamic-module-loader places this
|
| 32 |
+
# under transformers_modules.<...>.
|
| 33 |
+
from .vllm_llava_eurobert_audio import LlavaEuroBertAudioForVLLMEmbedding
|
| 34 |
+
except ImportError:
|
| 35 |
+
# Top-level import — works when this dir was added to PYTHONPATH
|
| 36 |
+
# (e.g. by vLLM's spawn child during inspect_model_cls).
|
| 37 |
+
from vllm_llava_eurobert_audio import LlavaEuroBertAudioForVLLMEmbedding
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
_TASK_KEY_MAP = {
|
| 41 |
+
"retrieval": "retrieval",
|
| 42 |
+
"text-matching": "text_matching",
|
| 43 |
+
"clustering": "clustering",
|
| 44 |
+
"classification": "classification",
|
| 45 |
+
}
|
| 46 |
+
_ATTN_MODULES = {"q_proj", "k_proj", "v_proj", "o_proj"}
|
| 47 |
+
_MLP_MODULES = {"gate_proj", "up_proj", "down_proj"}
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def _resolve_local_dir(model_path: str) -> Path:
|
| 51 |
+
if os.path.isdir(model_path):
|
| 52 |
+
return Path(model_path)
|
| 53 |
+
from huggingface_hub import snapshot_download
|
| 54 |
+
return Path(snapshot_download(
|
| 55 |
+
repo_id=model_path,
|
| 56 |
+
allow_patterns=["model.safetensors", "config.json", "adapters/*"],
|
| 57 |
+
))
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def _lora_target_key(layer_idx: int, module: str, side: str) -> str:
|
| 61 |
+
parent = "self_attn" if module in _ATTN_MODULES else "mlp"
|
| 62 |
+
return (
|
| 63 |
+
f"base_model.model.language_model.layers.{layer_idx}."
|
| 64 |
+
f"{parent}.{module}.lora_{side}.weight"
|
| 65 |
+
)
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def _materialize_task(base_dir: Path, task: str) -> dict[str, torch.Tensor]:
|
| 69 |
+
task_key = _TASK_KEY_MAP[task]
|
| 70 |
+
lora_dir = base_dir / "adapters" / task
|
| 71 |
+
|
| 72 |
+
base_cfg = json.loads((base_dir / "config.json").read_text())
|
| 73 |
+
special_tokens: list[int] = base_cfg["special_token_ids"]
|
| 74 |
+
adapter_cfg = json.loads((lora_dir / "adapter_config.json").read_text())
|
| 75 |
+
scale = adapter_cfg["lora_alpha"] / adapter_cfg["r"]
|
| 76 |
+
|
| 77 |
+
with safe_open(str(base_dir / "model.safetensors"), framework="pt") as f:
|
| 78 |
+
base = {k: f.get_tensor(k) for k in f.keys()}
|
| 79 |
+
with safe_open(str(lora_dir / "adapter_model.safetensors"), framework="pt") as f:
|
| 80 |
+
adapter = {k: f.get_tensor(k) for k in f.keys()}
|
| 81 |
+
|
| 82 |
+
merged: dict[str, torch.Tensor] = {}
|
| 83 |
+
|
| 84 |
+
for key, tensor in base.items():
|
| 85 |
+
if key.startswith("language_model.layers."):
|
| 86 |
+
parts = key.split(".")
|
| 87 |
+
# language_model.layers.{i}.{self_attn|mlp}.{module}.weight
|
| 88 |
+
if len(parts) == 6 and parts[-1] == "weight":
|
| 89 |
+
layer_idx = int(parts[2])
|
| 90 |
+
parent = parts[3]
|
| 91 |
+
module = parts[4]
|
| 92 |
+
if (parent == "self_attn" and module in _ATTN_MODULES) or (
|
| 93 |
+
parent == "mlp" and module in _MLP_MODULES
|
| 94 |
+
):
|
| 95 |
+
ak = _lora_target_key(layer_idx, module, "A")
|
| 96 |
+
bk = _lora_target_key(layer_idx, module, "B")
|
| 97 |
+
a = adapter.get(ak)
|
| 98 |
+
b = adapter.get(bk)
|
| 99 |
+
if a is not None and b is not None:
|
| 100 |
+
delta = (b.to(torch.float32) @ a.to(torch.float32)) * scale
|
| 101 |
+
tensor = (tensor.to(torch.float32) + delta).to(tensor.dtype)
|
| 102 |
+
merged[key] = tensor
|
| 103 |
+
|
| 104 |
+
elif key == "language_model.embed_tokens.weight":
|
| 105 |
+
tensor = tensor.clone()
|
| 106 |
+
te_key = f"task_token_embeddings.{task_key}"
|
| 107 |
+
te = base.get(te_key)
|
| 108 |
+
if te is not None:
|
| 109 |
+
for i, tid in enumerate(special_tokens):
|
| 110 |
+
tensor[tid] = te[i].to(tensor.dtype)
|
| 111 |
+
merged[key] = tensor
|
| 112 |
+
|
| 113 |
+
elif key.startswith("mergers."):
|
| 114 |
+
prefix = f"mergers.{task_key}."
|
| 115 |
+
if key.startswith(prefix):
|
| 116 |
+
merged["merger." + key[len(prefix):]] = tensor
|
| 117 |
+
|
| 118 |
+
elif key.startswith("audio_projectors."):
|
| 119 |
+
prefix = f"audio_projectors.{task_key}."
|
| 120 |
+
if key.startswith(prefix):
|
| 121 |
+
merged["audio_projector." + key[len(prefix):]] = tensor
|
| 122 |
+
|
| 123 |
+
elif key.startswith("task_token_embeddings."):
|
| 124 |
+
# Consumed into embed_tokens above.
|
| 125 |
+
pass
|
| 126 |
+
|
| 127 |
+
else:
|
| 128 |
+
merged[key] = tensor
|
| 129 |
+
|
| 130 |
+
return merged
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
class JinaV5OmniForVLLMEmbedding(LlavaEuroBertAudioForVLLMEmbedding):
|
| 134 |
+
"""vLLM wrapper for the base jina-embeddings-v5-omni-{nano,small}.
|
| 135 |
+
|
| 136 |
+
Reads JINA_V5_TASK env var; merges base + adapter[task] + task components at
|
| 137 |
+
load time. Resulting forward equals the jinaai/jina-embeddings-v5-omni-*-{task}
|
| 138 |
+
task variant.
|
| 139 |
+
"""
|
| 140 |
+
|
| 141 |
+
def __init__(self, *, vllm_config, prefix: str = ""):
|
| 142 |
+
super().__init__(vllm_config=vllm_config, prefix=prefix)
|
| 143 |
+
model = getattr(vllm_config.model_config, "model", None)
|
| 144 |
+
if not isinstance(model, str):
|
| 145 |
+
raise RuntimeError(
|
| 146 |
+
"JinaV5OmniForVLLMEmbedding requires a string model path; got "
|
| 147 |
+
f"{type(model).__name__}"
|
| 148 |
+
)
|
| 149 |
+
self._base_dir = _resolve_local_dir(model)
|
| 150 |
+
|
| 151 |
+
def load_weights(self, weights: Iterable[tuple[str, torch.Tensor]]) -> set[str]:
|
| 152 |
+
# Task precedence: config.task (hf_overrides) > env var. No silent
|
| 153 |
+
# fallback — running base+vLLM without picking a task would embed
|
| 154 |
+
# with the wrong adapter.
|
| 155 |
+
task = getattr(self.config, "task", None)
|
| 156 |
+
if task is None:
|
| 157 |
+
task = os.environ.get("JINA_V5_TASK")
|
| 158 |
+
if task is None:
|
| 159 |
+
raise ValueError(
|
| 160 |
+
"JinaV5OmniForVLLMEmbedding requires a task selection. Pass "
|
| 161 |
+
"hf_overrides={'task': X} to LLM(...) or set JINA_V5_TASK=X "
|
| 162 |
+
"in the environment, where X is one of "
|
| 163 |
+
f"{sorted(_TASK_KEY_MAP)}."
|
| 164 |
+
)
|
| 165 |
+
if task not in _TASK_KEY_MAP:
|
| 166 |
+
raise ValueError(
|
| 167 |
+
f"task must be one of {sorted(_TASK_KEY_MAP)}, got '{task}'"
|
| 168 |
+
)
|
| 169 |
+
# The streamed `weights` arg only covers base model.safetensors; we need
|
| 170 |
+
# the adapters too, so we materialize from disk directly and discard the
|
| 171 |
+
# incoming stream.
|
| 172 |
+
for _ in weights:
|
| 173 |
+
pass
|
| 174 |
+
materialized = _materialize_task(self._base_dir, task)
|
| 175 |
+
return super().load_weights(iter(materialized.items()))
|
vllm_llava_eurobert_audio.py
ADDED
|
@@ -0,0 +1,889 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
vLLM model implementation for LlavaEuroBertAudioForEmbedding (nano multimodal embedding).
|
| 3 |
+
|
| 4 |
+
Combines:
|
| 5 |
+
- Vision: Qwen3VL vision encoder + PretrainedMerger
|
| 6 |
+
- Audio: Qwen2_5OmniAudioEncoder (from Qwen2.5-Omni-7B) + Linear projector
|
| 7 |
+
- Text: LlamaModel / EuroBERT (bidirectional)
|
| 8 |
+
|
| 9 |
+
Usage:
|
| 10 |
+
from vllm import ModelRegistry
|
| 11 |
+
ModelRegistry.register_model(
|
| 12 |
+
"LlavaEuroBertAudioForEmbedding",
|
| 13 |
+
"vllm_llava_eurobert_audio:LlavaEuroBertAudioForVLLMEmbedding",
|
| 14 |
+
)
|
| 15 |
+
|
| 16 |
+
vllm serve /path/to/model --task embedding --trust-remote-code
|
| 17 |
+
"""
|
| 18 |
+
|
| 19 |
+
import os
|
| 20 |
+
from collections.abc import Iterable, Mapping, Sequence
|
| 21 |
+
from pathlib import Path
|
| 22 |
+
from typing import Annotated, Any, Literal, TypeAlias
|
| 23 |
+
|
| 24 |
+
import numpy as np
|
| 25 |
+
import torch
|
| 26 |
+
import torch.nn as nn
|
| 27 |
+
from transformers import BatchFeature
|
| 28 |
+
from transformers.models.qwen2_5_omni.configuration_qwen2_5_omni import (
|
| 29 |
+
Qwen2_5OmniAudioEncoderConfig,
|
| 30 |
+
)
|
| 31 |
+
from transformers.models.qwen2_5_omni.modeling_qwen2_5_omni import Qwen2_5OmniAudioEncoder
|
| 32 |
+
from transformers.models.qwen3_vl.configuration_qwen3_vl import Qwen3VLVisionConfig
|
| 33 |
+
from transformers.models.qwen3_vl.modeling_qwen3_vl import Qwen3VLVisionModel
|
| 34 |
+
from transformers.models.whisper import WhisperFeatureExtractor
|
| 35 |
+
|
| 36 |
+
from vllm.config import VllmConfig
|
| 37 |
+
try:
|
| 38 |
+
# vllm >= 0.11
|
| 39 |
+
from vllm.config.multimodal import BaseDummyOptions
|
| 40 |
+
except ImportError:
|
| 41 |
+
# vllm < 0.11 — BaseDummyOptions didn't exist; use a lightweight stand-in
|
| 42 |
+
# so the signature annotation still parses.
|
| 43 |
+
class BaseDummyOptions: # type: ignore[no-redef]
|
| 44 |
+
pass
|
| 45 |
+
try:
|
| 46 |
+
# vllm < 0.11: types re-exported via vllm.inputs
|
| 47 |
+
from vllm.inputs import MultiModalDataDict, ModalityData
|
| 48 |
+
except ImportError:
|
| 49 |
+
# vllm >= 0.11: moved to vllm.multimodal.inputs
|
| 50 |
+
from vllm.multimodal.inputs import MultiModalDataDict, ModalityData
|
| 51 |
+
from vllm.multimodal import MULTIMODAL_REGISTRY
|
| 52 |
+
from vllm.multimodal.inputs import (
|
| 53 |
+
AudioItem,
|
| 54 |
+
MultiModalFieldConfig,
|
| 55 |
+
MultiModalKwargsItems,
|
| 56 |
+
)
|
| 57 |
+
from vllm.multimodal.parse import (
|
| 58 |
+
DictEmbeddingItems,
|
| 59 |
+
ModalityDataItems,
|
| 60 |
+
MultiModalDataItems,
|
| 61 |
+
MultiModalDataParser,
|
| 62 |
+
)
|
| 63 |
+
try:
|
| 64 |
+
# vllm < 0.11
|
| 65 |
+
from vllm.multimodal.processing import BaseDummyInputsBuilder
|
| 66 |
+
except ImportError:
|
| 67 |
+
# vllm >= 0.11: moved to vllm.multimodal.profiling
|
| 68 |
+
from vllm.multimodal.profiling import BaseDummyInputsBuilder
|
| 69 |
+
from vllm.multimodal.processing import (
|
| 70 |
+
BaseMultiModalProcessor,
|
| 71 |
+
BaseProcessingInfo,
|
| 72 |
+
PromptReplacement,
|
| 73 |
+
PromptUpdate,
|
| 74 |
+
)
|
| 75 |
+
from vllm.sequence import IntermediateTensors
|
| 76 |
+
from vllm.utils.tensor_schema import TensorSchema, TensorShape
|
| 77 |
+
from vllm.model_executor.models.interfaces import (
|
| 78 |
+
MultiModalEmbeddings,
|
| 79 |
+
SupportsMultiModal,
|
| 80 |
+
SupportsPP,
|
| 81 |
+
)
|
| 82 |
+
from vllm.model_executor.models.qwen2_vl import _create_qwen2vl_field_factory
|
| 83 |
+
from vllm.model_executor.models.utils import (
|
| 84 |
+
AutoWeightsLoader,
|
| 85 |
+
init_vllm_registered_model,
|
| 86 |
+
maybe_prefix,
|
| 87 |
+
)
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
# --------------------------------------------------------------------------- #
|
| 91 |
+
# PretrainedMerger (same architecture as HuggingFace version)
|
| 92 |
+
# --------------------------------------------------------------------------- #
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
class PretrainedMerger(nn.Module):
|
| 96 |
+
def __init__(self, hidden_size, out_hidden_size, spatial_merge_size=2):
|
| 97 |
+
super().__init__()
|
| 98 |
+
self.hidden_size = hidden_size * (spatial_merge_size ** 2)
|
| 99 |
+
self.norm = nn.LayerNorm(hidden_size, eps=1e-6)
|
| 100 |
+
self.linear_fc1 = nn.Linear(self.hidden_size, self.hidden_size)
|
| 101 |
+
self.act = nn.GELU()
|
| 102 |
+
self.linear_fc2 = nn.Linear(self.hidden_size, out_hidden_size)
|
| 103 |
+
|
| 104 |
+
def forward(self, x):
|
| 105 |
+
x = self.norm(x)
|
| 106 |
+
x = x.view(-1, self.hidden_size)
|
| 107 |
+
x = self.linear_fc2(self.act(self.linear_fc1(x)))
|
| 108 |
+
return x
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
# --------------------------------------------------------------------------- #
|
| 112 |
+
# Audio input schemas
|
| 113 |
+
# --------------------------------------------------------------------------- #
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
class NanoAudioFeatureInputs(TensorSchema):
|
| 117 |
+
type: Literal["audio_features"]
|
| 118 |
+
input_features: Annotated[
|
| 119 |
+
torch.Tensor | list[torch.Tensor],
|
| 120 |
+
TensorShape("na", "nmb", 3000),
|
| 121 |
+
]
|
| 122 |
+
feature_attention_mask: Annotated[
|
| 123 |
+
torch.Tensor,
|
| 124 |
+
TensorShape("na", 3000),
|
| 125 |
+
]
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
class NanoAudioEmbeddingInputs(TensorSchema):
|
| 129 |
+
type: Literal["audio_embeds"] = "audio_embeds"
|
| 130 |
+
audio_embeds: Annotated[
|
| 131 |
+
list[torch.Tensor],
|
| 132 |
+
TensorShape("bn", "naf", "hs", dynamic_dims={"naf"}),
|
| 133 |
+
]
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
NanoAudioInputs: TypeAlias = NanoAudioFeatureInputs | NanoAudioEmbeddingInputs
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
def _get_feat_extract_output_lengths(input_lengths: torch.Tensor):
|
| 140 |
+
feat_lengths = (input_lengths - 1) // 2 + 1
|
| 141 |
+
output_lengths = (feat_lengths - 2) // 2 + 1
|
| 142 |
+
return feat_lengths, output_lengths
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
# --------------------------------------------------------------------------- #
|
| 146 |
+
# Processing info
|
| 147 |
+
# --------------------------------------------------------------------------- #
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
class NanoMMAudioMultiModalDataParser(MultiModalDataParser):
|
| 151 |
+
def __init__(self, target_sr, target_channels, expected_hidden_size=None):
|
| 152 |
+
super().__init__(
|
| 153 |
+
target_sr=target_sr,
|
| 154 |
+
target_channels=target_channels,
|
| 155 |
+
expected_hidden_size=expected_hidden_size,
|
| 156 |
+
)
|
| 157 |
+
|
| 158 |
+
def _parse_audio_data(
|
| 159 |
+
self,
|
| 160 |
+
data: dict[str, torch.Tensor] | ModalityData[AudioItem],
|
| 161 |
+
) -> ModalityDataItems[Any, Any] | None:
|
| 162 |
+
if isinstance(data, dict):
|
| 163 |
+
return DictEmbeddingItems(
|
| 164 |
+
data,
|
| 165 |
+
modality="audio",
|
| 166 |
+
required_fields={"audio_embeds"},
|
| 167 |
+
fields_factory=lambda hf: dict(
|
| 168 |
+
audio_embeds=MultiModalFieldConfig.batched("audio"),
|
| 169 |
+
input_features=MultiModalFieldConfig.batched("audio"),
|
| 170 |
+
feature_attention_mask=MultiModalFieldConfig.batched("audio"),
|
| 171 |
+
),
|
| 172 |
+
)
|
| 173 |
+
return super()._parse_audio_data(data)
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
class NanoMMProcessingInfo(BaseProcessingInfo):
|
| 177 |
+
def get_hf_config(self):
|
| 178 |
+
return self.ctx.get_hf_config()
|
| 179 |
+
|
| 180 |
+
def get_feature_extractor(self, **kwargs) -> WhisperFeatureExtractor:
|
| 181 |
+
return WhisperFeatureExtractor(feature_size=128)
|
| 182 |
+
|
| 183 |
+
def get_data_parser(self):
|
| 184 |
+
feature_extractor = self.get_feature_extractor()
|
| 185 |
+
return NanoMMAudioMultiModalDataParser(
|
| 186 |
+
target_sr=feature_extractor.sampling_rate,
|
| 187 |
+
target_channels=1,
|
| 188 |
+
expected_hidden_size=self._get_expected_hidden_size(),
|
| 189 |
+
)
|
| 190 |
+
|
| 191 |
+
def get_supported_mm_limits(self) -> Mapping[str, int | None]:
|
| 192 |
+
return {"image": None, "video": None, "audio": None}
|
| 193 |
+
|
| 194 |
+
def get_mm_max_tokens_per_item(
|
| 195 |
+
self,
|
| 196 |
+
seq_len: int,
|
| 197 |
+
mm_counts: Mapping[str, int] | None = None,
|
| 198 |
+
) -> Mapping[str, int]:
|
| 199 |
+
result = {}
|
| 200 |
+
mm_counts = mm_counts or {}
|
| 201 |
+
|
| 202 |
+
hf_config = self.get_hf_config()
|
| 203 |
+
vis_cfg = hf_config.vision_config
|
| 204 |
+
if isinstance(vis_cfg, dict):
|
| 205 |
+
spatial_merge_size = vis_cfg.get("spatial_merge_size", 2)
|
| 206 |
+
else:
|
| 207 |
+
spatial_merge_size = getattr(vis_cfg, "spatial_merge_size", 2)
|
| 208 |
+
|
| 209 |
+
# Always return per-item max for all modalities — vLLM calls this
|
| 210 |
+
# during profiling with empty mm_counts; a missing key is treated as 0
|
| 211 |
+
# which causes "At most 0 video(s) may be provided" errors.
|
| 212 |
+
result["image"] = 256 // (spatial_merge_size ** 2)
|
| 213 |
+
|
| 214 |
+
# 32-frame videos at typical resolution produce ~7040 tokens
|
| 215 |
+
# (measured: 16 frames → 3520 tokens with spatial_merge_size=1).
|
| 216 |
+
# Cap at 64 frames worth to handle evaluation edge cases.
|
| 217 |
+
result["video"] = 64 * 256 // max(spatial_merge_size ** 2, 1)
|
| 218 |
+
|
| 219 |
+
feature_extractor = self.get_feature_extractor()
|
| 220 |
+
chunk_length = min(feature_extractor.chunk_length, 30)
|
| 221 |
+
audio_len = int(chunk_length * feature_extractor.sampling_rate)
|
| 222 |
+
hop_length = feature_extractor.hop_length
|
| 223 |
+
max_mel_seq_len = audio_len // hop_length
|
| 224 |
+
input_lengths = torch.tensor([max_mel_seq_len], dtype=torch.long)
|
| 225 |
+
_, output_lengths = _get_feat_extract_output_lengths(input_lengths)
|
| 226 |
+
result["audio"] = int(output_lengths.item())
|
| 227 |
+
|
| 228 |
+
return result
|
| 229 |
+
|
| 230 |
+
|
| 231 |
+
# --------------------------------------------------------------------------- #
|
| 232 |
+
# Dummy inputs builder
|
| 233 |
+
# --------------------------------------------------------------------------- #
|
| 234 |
+
|
| 235 |
+
|
| 236 |
+
class NanoMMDummyInputsBuilder(BaseDummyInputsBuilder[NanoMMProcessingInfo]):
|
| 237 |
+
def get_dummy_text(self, mm_counts: Mapping[str, int]) -> str:
|
| 238 |
+
text = ""
|
| 239 |
+
num_images = mm_counts.get("image", 0)
|
| 240 |
+
num_videos = mm_counts.get("video", 0)
|
| 241 |
+
num_audios = mm_counts.get("audio", 0)
|
| 242 |
+
|
| 243 |
+
image_token = "<image>"
|
| 244 |
+
video_token = "<image>"
|
| 245 |
+
audio_token = "<|audio_bos|><|AUDIO|><|audio_eos|>"
|
| 246 |
+
|
| 247 |
+
text += image_token * num_images
|
| 248 |
+
text += video_token * num_videos
|
| 249 |
+
text += audio_token * num_audios
|
| 250 |
+
return text
|
| 251 |
+
|
| 252 |
+
def get_dummy_mm_data(
|
| 253 |
+
self,
|
| 254 |
+
seq_len: int,
|
| 255 |
+
mm_counts: Mapping[str, int],
|
| 256 |
+
mm_options: Mapping[str, BaseDummyOptions],
|
| 257 |
+
) -> MultiModalDataDict:
|
| 258 |
+
result: dict[str, Any] = {}
|
| 259 |
+
|
| 260 |
+
num_images = mm_counts.get("image", 0)
|
| 261 |
+
if num_images > 0:
|
| 262 |
+
result["image"] = self._get_dummy_images(
|
| 263 |
+
width=224, height=224, num_images=num_images,
|
| 264 |
+
overrides=mm_options.get("image"),
|
| 265 |
+
)
|
| 266 |
+
|
| 267 |
+
num_videos = mm_counts.get("video", 0)
|
| 268 |
+
if num_videos > 0:
|
| 269 |
+
result["video"] = self._get_dummy_videos(
|
| 270 |
+
width=224, height=224, num_frames=2, num_videos=num_videos,
|
| 271 |
+
overrides=mm_options.get("video"),
|
| 272 |
+
)
|
| 273 |
+
|
| 274 |
+
num_audios = mm_counts.get("audio", 0)
|
| 275 |
+
if num_audios > 0:
|
| 276 |
+
feature_extractor = self.info.get_feature_extractor()
|
| 277 |
+
sampling_rate = feature_extractor.sampling_rate
|
| 278 |
+
audio_len = feature_extractor.chunk_length * sampling_rate
|
| 279 |
+
result["audio"] = self._get_dummy_audios(
|
| 280 |
+
length=audio_len, num_audios=num_audios,
|
| 281 |
+
overrides=mm_options.get("audio"),
|
| 282 |
+
)
|
| 283 |
+
|
| 284 |
+
return result
|
| 285 |
+
|
| 286 |
+
|
| 287 |
+
# --------------------------------------------------------------------------- #
|
| 288 |
+
# Multimodal processor
|
| 289 |
+
# --------------------------------------------------------------------------- #
|
| 290 |
+
|
| 291 |
+
|
| 292 |
+
class NanoMMMultiModalProcessor(BaseMultiModalProcessor[NanoMMProcessingInfo]):
|
| 293 |
+
def _call_hf_processor(
|
| 294 |
+
self,
|
| 295 |
+
prompt: str,
|
| 296 |
+
mm_data: Mapping[str, object],
|
| 297 |
+
mm_kwargs: Mapping[str, Any],
|
| 298 |
+
tok_kwargs: Mapping[str, object],
|
| 299 |
+
) -> BatchFeature:
|
| 300 |
+
if not isinstance(mm_data, dict):
|
| 301 |
+
mm_data = dict(mm_data)
|
| 302 |
+
audios = mm_data.pop("audios", [])
|
| 303 |
+
if audios:
|
| 304 |
+
mm_data["audio"] = audios
|
| 305 |
+
|
| 306 |
+
has_audio = bool(mm_data.get("audio", []))
|
| 307 |
+
has_images = bool(mm_data.get("images", []))
|
| 308 |
+
has_videos = bool(mm_data.get("videos", []))
|
| 309 |
+
|
| 310 |
+
if not has_audio and not has_images and not has_videos:
|
| 311 |
+
prompt_ids = self.info.get_tokenizer().encode(prompt)
|
| 312 |
+
prompt_ids = self._apply_hf_processor_tokens_only(prompt_ids)
|
| 313 |
+
return BatchFeature(dict(input_ids=[prompt_ids]), tensor_type="pt")
|
| 314 |
+
|
| 315 |
+
if has_audio and not has_images and not has_videos:
|
| 316 |
+
feature_extractor = self.info.get_feature_extractor(**mm_kwargs)
|
| 317 |
+
tokenizer = self.info.get_tokenizer()
|
| 318 |
+
|
| 319 |
+
audio_items = mm_data.get("audio", [])
|
| 320 |
+
if not isinstance(audio_items, list):
|
| 321 |
+
audio_items = [audio_items]
|
| 322 |
+
|
| 323 |
+
def _to_audio_array(item: object) -> np.ndarray:
|
| 324 |
+
if hasattr(item, "data"):
|
| 325 |
+
item = item.data
|
| 326 |
+
if isinstance(item, tuple) and len(item) >= 1:
|
| 327 |
+
item = item[0]
|
| 328 |
+
if isinstance(item, dict):
|
| 329 |
+
for key in ("array", "audio", "data", "samples"):
|
| 330 |
+
if key in item:
|
| 331 |
+
item = item[key]
|
| 332 |
+
break
|
| 333 |
+
if hasattr(item, "array"):
|
| 334 |
+
item = item.array
|
| 335 |
+
if hasattr(item, "audio"):
|
| 336 |
+
item = item.audio
|
| 337 |
+
arr = np.asarray(item, dtype=np.float32)
|
| 338 |
+
if arr.ndim > 1:
|
| 339 |
+
arr = arr.squeeze()
|
| 340 |
+
return arr
|
| 341 |
+
|
| 342 |
+
processed_audio = []
|
| 343 |
+
for item in audio_items:
|
| 344 |
+
processed_audio.append(_to_audio_array(item))
|
| 345 |
+
|
| 346 |
+
audio_features = feature_extractor(
|
| 347 |
+
processed_audio,
|
| 348 |
+
sampling_rate=feature_extractor.sampling_rate,
|
| 349 |
+
return_tensors="pt",
|
| 350 |
+
padding="max_length",
|
| 351 |
+
)
|
| 352 |
+
max_mel_len = audio_features["input_features"].shape[-1]
|
| 353 |
+
|
| 354 |
+
# Keep audio prompts aligned with torch reference path
|
| 355 |
+
# (audio BOS + repeated audio token + audio EOS, no added special token).
|
| 356 |
+
prompt_ids = tokenizer.encode(prompt, add_special_tokens=False)
|
| 357 |
+
prompt_ids = self._apply_hf_processor_tokens_only(prompt_ids)
|
| 358 |
+
|
| 359 |
+
feature_attention_mask = torch.zeros(
|
| 360 |
+
(audio_features["input_features"].shape[0], max_mel_len),
|
| 361 |
+
dtype=torch.long,
|
| 362 |
+
)
|
| 363 |
+
feature_attention_mask[:] = 1
|
| 364 |
+
output = {
|
| 365 |
+
"input_ids": [prompt_ids],
|
| 366 |
+
"input_features": audio_features["input_features"],
|
| 367 |
+
"feature_attention_mask": feature_attention_mask,
|
| 368 |
+
}
|
| 369 |
+
return BatchFeature(output, tensor_type="pt")
|
| 370 |
+
|
| 371 |
+
if has_audio:
|
| 372 |
+
feature_extractor = self.info.get_feature_extractor(**mm_kwargs)
|
| 373 |
+
mm_kwargs = dict(**mm_kwargs, sampling_rate=feature_extractor.sampling_rate)
|
| 374 |
+
|
| 375 |
+
if has_videos:
|
| 376 |
+
mm_kwargs = dict(mm_kwargs, do_sample_frames=False)
|
| 377 |
+
|
| 378 |
+
return super()._call_hf_processor(
|
| 379 |
+
prompt=prompt,
|
| 380 |
+
mm_data=mm_data,
|
| 381 |
+
mm_kwargs=mm_kwargs,
|
| 382 |
+
tok_kwargs=tok_kwargs,
|
| 383 |
+
)
|
| 384 |
+
|
| 385 |
+
def _get_mm_fields_config(
|
| 386 |
+
self,
|
| 387 |
+
hf_inputs: BatchFeature,
|
| 388 |
+
hf_processor_mm_kwargs: Mapping[str, object],
|
| 389 |
+
) -> Mapping[str, MultiModalFieldConfig]:
|
| 390 |
+
hf_cfg = self.info.get_hf_config()
|
| 391 |
+
spatial_merge_size = getattr(hf_cfg.vision_config, "spatial_merge_size", 2)
|
| 392 |
+
fields = dict(_create_qwen2vl_field_factory(spatial_merge_size)(hf_inputs))
|
| 393 |
+
if "input_features" in hf_inputs:
|
| 394 |
+
fields["input_features"] = MultiModalFieldConfig.batched("audio")
|
| 395 |
+
if "feature_attention_mask" in hf_inputs:
|
| 396 |
+
fields["feature_attention_mask"] = MultiModalFieldConfig.batched(
|
| 397 |
+
"audio", keep_on_cpu=True
|
| 398 |
+
)
|
| 399 |
+
if "audio_embeds" in hf_inputs:
|
| 400 |
+
fields["audio_embeds"] = MultiModalFieldConfig.batched("audio")
|
| 401 |
+
return fields
|
| 402 |
+
|
| 403 |
+
def _get_prompt_updates(
|
| 404 |
+
self,
|
| 405 |
+
mm_items: MultiModalDataItems,
|
| 406 |
+
hf_processor_mm_kwargs: Mapping[str, object],
|
| 407 |
+
out_mm_kwargs: MultiModalKwargsItems,
|
| 408 |
+
) -> Sequence[PromptUpdate]:
|
| 409 |
+
updates = []
|
| 410 |
+
hf_config = self.info.get_hf_config()
|
| 411 |
+
out_mm_data = out_mm_kwargs.get_data()
|
| 412 |
+
|
| 413 |
+
image_token_index = getattr(hf_config, "image_token_index", None)
|
| 414 |
+
audio_token_id = getattr(hf_config, "audio_token_id", None)
|
| 415 |
+
has_image_items = any(
|
| 416 |
+
key in out_mm_data for key in ("pixel_values", "image_embeds", "image_grid_thw")
|
| 417 |
+
)
|
| 418 |
+
has_video_items = any(
|
| 419 |
+
key in out_mm_data for key in ("pixel_values_videos", "video_embeds", "video_grid_thw")
|
| 420 |
+
)
|
| 421 |
+
has_audio_items = any(
|
| 422 |
+
key in out_mm_data
|
| 423 |
+
for key in ("audio_embeds", "input_features", "feature_attention_mask")
|
| 424 |
+
)
|
| 425 |
+
|
| 426 |
+
spatial_merge_size = getattr(
|
| 427 |
+
hf_config.vision_config, "spatial_merge_size", 2
|
| 428 |
+
)
|
| 429 |
+
|
| 430 |
+
def _vision_replacement(grid_thw, item_idx: int):
|
| 431 |
+
if grid_thw is not None:
|
| 432 |
+
thw = grid_thw[item_idx]
|
| 433 |
+
t, h, w = thw.tolist() if hasattr(thw, "tolist") else (int(thw[0]), int(thw[1]), int(thw[2]))
|
| 434 |
+
n = int(t) * (int(h) // spatial_merge_size) * (int(w) // spatial_merge_size)
|
| 435 |
+
else:
|
| 436 |
+
n = 1
|
| 437 |
+
return [image_token_index] * n
|
| 438 |
+
|
| 439 |
+
if image_token_index is not None and has_image_items:
|
| 440 |
+
image_grid_thw = out_mm_data.get("image_grid_thw")
|
| 441 |
+
updates.append(
|
| 442 |
+
PromptReplacement(
|
| 443 |
+
modality="image",
|
| 444 |
+
target=[image_token_index],
|
| 445 |
+
replacement=lambda idx: _vision_replacement(image_grid_thw, idx),
|
| 446 |
+
)
|
| 447 |
+
)
|
| 448 |
+
|
| 449 |
+
if image_token_index is not None and has_video_items:
|
| 450 |
+
# processing_llava_eurobert.py maps both image and video tokens to
|
| 451 |
+
# "<image>"; the prompt uses <image> for video too.
|
| 452 |
+
video_grid_thw = out_mm_data.get("video_grid_thw")
|
| 453 |
+
updates.append(
|
| 454 |
+
PromptReplacement(
|
| 455 |
+
modality="video",
|
| 456 |
+
target=[image_token_index],
|
| 457 |
+
replacement=lambda idx: _vision_replacement(video_grid_thw, idx),
|
| 458 |
+
)
|
| 459 |
+
)
|
| 460 |
+
|
| 461 |
+
if audio_token_id is not None and has_audio_items:
|
| 462 |
+
feature_attention_mask = out_mm_data.get("feature_attention_mask")
|
| 463 |
+
if feature_attention_mask is not None:
|
| 464 |
+
assert isinstance(feature_attention_mask, torch.Tensor)
|
| 465 |
+
_, audio_output_lens = _get_feat_extract_output_lengths(
|
| 466 |
+
feature_attention_mask.sum(-1)
|
| 467 |
+
)
|
| 468 |
+
audio_output_lengths = audio_output_lens.tolist()
|
| 469 |
+
else:
|
| 470 |
+
audio_output_lengths = []
|
| 471 |
+
|
| 472 |
+
def get_audio_replacement(item_idx: int):
|
| 473 |
+
if audio_output_lengths:
|
| 474 |
+
n = audio_output_lengths[item_idx]
|
| 475 |
+
elif "audio_embeds" in out_mm_data:
|
| 476 |
+
embeds = out_mm_data["audio_embeds"][item_idx]
|
| 477 |
+
n = embeds.shape[0]
|
| 478 |
+
elif "input_features" in out_mm_data:
|
| 479 |
+
raw_feats = out_mm_data["input_features"]
|
| 480 |
+
if isinstance(raw_feats, torch.Tensor):
|
| 481 |
+
feats = raw_feats[item_idx]
|
| 482 |
+
else:
|
| 483 |
+
feat_item = raw_feats[item_idx]
|
| 484 |
+
feats = feat_item.data if hasattr(feat_item, "data") else feat_item
|
| 485 |
+
feature_len = int(feats.shape[-1])
|
| 486 |
+
_, output_lengths = _get_feat_extract_output_lengths(
|
| 487 |
+
torch.tensor([feature_len], dtype=torch.long)
|
| 488 |
+
)
|
| 489 |
+
n = int(output_lengths.item())
|
| 490 |
+
else:
|
| 491 |
+
n = 1
|
| 492 |
+
return [audio_token_id] * n
|
| 493 |
+
|
| 494 |
+
updates.append(
|
| 495 |
+
PromptReplacement(
|
| 496 |
+
modality="audio",
|
| 497 |
+
target=[audio_token_id],
|
| 498 |
+
replacement=get_audio_replacement,
|
| 499 |
+
)
|
| 500 |
+
)
|
| 501 |
+
|
| 502 |
+
return updates
|
| 503 |
+
|
| 504 |
+
|
| 505 |
+
# --------------------------------------------------------------------------- #
|
| 506 |
+
# Model
|
| 507 |
+
# --------------------------------------------------------------------------- #
|
| 508 |
+
|
| 509 |
+
|
| 510 |
+
@MULTIMODAL_REGISTRY.register_processor(
|
| 511 |
+
NanoMMMultiModalProcessor,
|
| 512 |
+
info=NanoMMProcessingInfo,
|
| 513 |
+
dummy_inputs=NanoMMDummyInputsBuilder,
|
| 514 |
+
)
|
| 515 |
+
class LlavaEuroBertAudioForVLLMEmbedding(nn.Module, SupportsMultiModal, SupportsPP):
|
| 516 |
+
"""vLLM model for LlavaEuroBertAudioForEmbedding (nano multimodal embedding)."""
|
| 517 |
+
|
| 518 |
+
@classmethod
|
| 519 |
+
def get_placeholder_str(cls, modality: str, i: int) -> str | None:
|
| 520 |
+
if modality == "image":
|
| 521 |
+
return "<image>"
|
| 522 |
+
if modality == "video":
|
| 523 |
+
return "<image>"
|
| 524 |
+
if modality.startswith("audio"):
|
| 525 |
+
return f"Audio {i}: <|audio_bos|><|AUDIO|><|audio_eos|>"
|
| 526 |
+
return None
|
| 527 |
+
|
| 528 |
+
def __init__(self, *, vllm_config: VllmConfig, prefix: str = ""):
|
| 529 |
+
super().__init__()
|
| 530 |
+
config = vllm_config.model_config.hf_config
|
| 531 |
+
self.config = config
|
| 532 |
+
self.audio_token_id = getattr(config, "audio_token_id", None)
|
| 533 |
+
|
| 534 |
+
vis_cfg = config.vision_config
|
| 535 |
+
if not isinstance(vis_cfg, Qwen3VLVisionConfig):
|
| 536 |
+
if hasattr(vis_cfg, "to_dict"):
|
| 537 |
+
d = vis_cfg.to_dict()
|
| 538 |
+
else:
|
| 539 |
+
d = dict(vis_cfg)
|
| 540 |
+
d.pop("model_type", None)
|
| 541 |
+
d.pop("transformers_version", None)
|
| 542 |
+
vis_cfg = Qwen3VLVisionConfig(**d)
|
| 543 |
+
vis_cfg.deepstack_visual_indexes = []
|
| 544 |
+
|
| 545 |
+
txt_cfg = config.text_config
|
| 546 |
+
if isinstance(txt_cfg, dict):
|
| 547 |
+
from transformers import LlamaConfig
|
| 548 |
+
txt_cfg = LlamaConfig(**txt_cfg)
|
| 549 |
+
# transformers 5.x aliases rope_scaling and rope_parameters via the
|
| 550 |
+
# same proxy. Assigning rope_scaling = None silently nulls
|
| 551 |
+
# rope_parameters too, making vLLM's get_rope fall back to
|
| 552 |
+
# base=10000 (default Llama) instead of the model's rope_theta.
|
| 553 |
+
# Set only rope_theta + rope_parameters; never touch rope_scaling.
|
| 554 |
+
rope_params = getattr(txt_cfg, "rope_parameters", None)
|
| 555 |
+
if rope_params:
|
| 556 |
+
rope_theta = float(rope_params.get("rope_theta", 10000.0))
|
| 557 |
+
clean = dict(rope_params)
|
| 558 |
+
clean["rope_theta"] = rope_theta
|
| 559 |
+
txt_cfg.rope_theta = rope_theta
|
| 560 |
+
txt_cfg.rope_parameters = clean
|
| 561 |
+
text_hidden = txt_cfg.hidden_size
|
| 562 |
+
|
| 563 |
+
aud_cfg = config.audio_config
|
| 564 |
+
if isinstance(aud_cfg, dict):
|
| 565 |
+
aud_cfg = Qwen2_5OmniAudioEncoderConfig(**aud_cfg)
|
| 566 |
+
|
| 567 |
+
spatial_merge_size = getattr(vis_cfg, "spatial_merge_size", 2)
|
| 568 |
+
self._spatial_merge_size = spatial_merge_size
|
| 569 |
+
|
| 570 |
+
with self._mark_tower_model(vllm_config, {"image", "video"}):
|
| 571 |
+
self.vision_tower = Qwen3VLVisionModel(vis_cfg)
|
| 572 |
+
self.vision_tower.merger = nn.Identity()
|
| 573 |
+
self.vision_tower.deepstack_merger_list = nn.ModuleList()
|
| 574 |
+
self.vision_tower.deepstack_visual_indexes = []
|
| 575 |
+
|
| 576 |
+
self.merger = PretrainedMerger(
|
| 577 |
+
vis_cfg.hidden_size, text_hidden, spatial_merge_size
|
| 578 |
+
)
|
| 579 |
+
|
| 580 |
+
with self._mark_tower_model(vllm_config, "audio"):
|
| 581 |
+
self.audio_tower = Qwen2_5OmniAudioEncoder(aud_cfg)
|
| 582 |
+
self.audio_tower.proj = nn.Identity() # fused into audio_projector
|
| 583 |
+
d_model = getattr(aud_cfg, "d_model", 1280)
|
| 584 |
+
self.audio_projector = nn.Linear(d_model, text_hidden)
|
| 585 |
+
|
| 586 |
+
self.multi_modal_projector = nn.Identity()
|
| 587 |
+
self.lm_head = nn.Identity()
|
| 588 |
+
|
| 589 |
+
with self._mark_language_model(vllm_config):
|
| 590 |
+
self.language_model = init_vllm_registered_model(
|
| 591 |
+
vllm_config=vllm_config,
|
| 592 |
+
hf_config=txt_cfg,
|
| 593 |
+
prefix=maybe_prefix(prefix, "language_model"),
|
| 594 |
+
architectures=["LlamaBidirectionalModel"],
|
| 595 |
+
)
|
| 596 |
+
|
| 597 |
+
self.make_empty_intermediate_tensors = (
|
| 598 |
+
self.language_model.make_empty_intermediate_tensors
|
| 599 |
+
)
|
| 600 |
+
self._init_audio_alignment(text_hidden, vllm_config)
|
| 601 |
+
# Default audio prompt path expands to:
|
| 602 |
+
# <audio_bos> + 750 audio tokens + <audio_eos> = 752 tokens.
|
| 603 |
+
self._audio_default_seq_len = 752
|
| 604 |
+
# Set in embed_multimodal when the batch contains audio; consumed and
|
| 605 |
+
# cleared in forward so the seq_len fallback never fires for text-only.
|
| 606 |
+
self._pending_audio_in_batch = False
|
| 607 |
+
|
| 608 |
+
def _init_audio_alignment(self, hidden_size: int, vllm_config: VllmConfig) -> None:
|
| 609 |
+
if self.audio_token_id is None:
|
| 610 |
+
return
|
| 611 |
+
if os.getenv("JINA_OMNI_DISABLE_AUDIO_ALIGNMENT") == "1":
|
| 612 |
+
return
|
| 613 |
+
|
| 614 |
+
candidate_paths: list[Path] = [Path(__file__).with_name("audio_linear_alignment.pt")]
|
| 615 |
+
model_path = getattr(vllm_config.model_config, "model", None)
|
| 616 |
+
if isinstance(model_path, str):
|
| 617 |
+
candidate_paths.append(Path(model_path) / "audio_linear_alignment.pt")
|
| 618 |
+
|
| 619 |
+
alignment_path = next((p for p in candidate_paths if p.exists()), None)
|
| 620 |
+
|
| 621 |
+
if alignment_path is None and isinstance(model_path, str) and "/" in model_path:
|
| 622 |
+
try:
|
| 623 |
+
from huggingface_hub import hf_hub_download
|
| 624 |
+
alignment_path = Path(hf_hub_download(
|
| 625 |
+
model_path, "audio_linear_alignment.pt",
|
| 626 |
+
))
|
| 627 |
+
except Exception:
|
| 628 |
+
pass
|
| 629 |
+
|
| 630 |
+
if alignment_path is None:
|
| 631 |
+
return
|
| 632 |
+
|
| 633 |
+
payload = torch.load(alignment_path, map_location="cpu")
|
| 634 |
+
matrix = payload.get("W") if isinstance(payload, dict) else payload
|
| 635 |
+
if not isinstance(matrix, torch.Tensor):
|
| 636 |
+
return
|
| 637 |
+
if matrix.ndim != 2:
|
| 638 |
+
return
|
| 639 |
+
if matrix.shape[0] != hidden_size or matrix.shape[1] != hidden_size:
|
| 640 |
+
return
|
| 641 |
+
|
| 642 |
+
self.register_buffer(
|
| 643 |
+
"audio_linear_alignment", matrix.to(torch.float32), persistent=False
|
| 644 |
+
)
|
| 645 |
+
|
| 646 |
+
def _apply_audio_alignment(
|
| 647 |
+
self,
|
| 648 |
+
hidden_states: torch.Tensor,
|
| 649 |
+
input_ids: torch.Tensor | None,
|
| 650 |
+
positions: torch.Tensor | None,
|
| 651 |
+
has_audio: bool = False,
|
| 652 |
+
) -> torch.Tensor:
|
| 653 |
+
alignment_matrix = getattr(self, "audio_linear_alignment", None)
|
| 654 |
+
if alignment_matrix is None:
|
| 655 |
+
return hidden_states
|
| 656 |
+
if positions is None:
|
| 657 |
+
return hidden_states
|
| 658 |
+
|
| 659 |
+
flat_positions = positions.reshape(-1)
|
| 660 |
+
if flat_positions.shape[0] != hidden_states.shape[0]:
|
| 661 |
+
return hidden_states
|
| 662 |
+
flat_input_ids = input_ids.reshape(-1) if input_ids is not None else None
|
| 663 |
+
|
| 664 |
+
seq_starts = torch.nonzero(flat_positions.eq(0), as_tuple=False).flatten()
|
| 665 |
+
if seq_starts.numel() == 0:
|
| 666 |
+
seq_starts = flat_positions.new_tensor([0])
|
| 667 |
+
elif seq_starts[0].item() != 0:
|
| 668 |
+
seq_starts = torch.cat([flat_positions.new_tensor([0]), seq_starts], dim=0)
|
| 669 |
+
|
| 670 |
+
seq_ends = torch.cat(
|
| 671 |
+
[seq_starts[1:], flat_positions.new_tensor([flat_positions.numel()])], dim=0
|
| 672 |
+
)
|
| 673 |
+
|
| 674 |
+
alignment_matrix = alignment_matrix.to(
|
| 675 |
+
device=hidden_states.device, dtype=torch.float32
|
| 676 |
+
)
|
| 677 |
+
aligned_hidden_states = hidden_states.float()
|
| 678 |
+
for start, end in zip(seq_starts.tolist(), seq_ends.tolist()):
|
| 679 |
+
seq_len = end - start
|
| 680 |
+
apply_alignment = False
|
| 681 |
+
|
| 682 |
+
if flat_input_ids is not None and self.audio_token_id is not None:
|
| 683 |
+
apply_alignment = bool(torch.any(flat_input_ids[start:end].eq(self.audio_token_id)))
|
| 684 |
+
elif has_audio:
|
| 685 |
+
# vLLM pooling runner passes only inputs_embeds (input_ids=None).
|
| 686 |
+
# Only trust the default-length marker when embed_multimodal
|
| 687 |
+
# actually processed audio for this batch — otherwise a text
|
| 688 |
+
# prompt that happens to pack to 752 tokens would be poisoned.
|
| 689 |
+
apply_alignment = seq_len == self._audio_default_seq_len
|
| 690 |
+
|
| 691 |
+
if apply_alignment:
|
| 692 |
+
aligned_hidden_states[start:end] = aligned_hidden_states[start:end] @ alignment_matrix
|
| 693 |
+
return aligned_hidden_states.to(hidden_states.dtype)
|
| 694 |
+
|
| 695 |
+
# ---- vision processing ---- #
|
| 696 |
+
|
| 697 |
+
def _process_image_input(self, pixel_values, image_grid_thw):
|
| 698 |
+
vision_output = self.vision_tower(
|
| 699 |
+
hidden_states=pixel_values, grid_thw=image_grid_thw
|
| 700 |
+
)
|
| 701 |
+
raw_hidden = vision_output[0] if isinstance(vision_output, tuple) else vision_output[0]
|
| 702 |
+
|
| 703 |
+
image_features = self.merger(raw_hidden)
|
| 704 |
+
|
| 705 |
+
merge = self._spatial_merge_size
|
| 706 |
+
tokens_per_image = []
|
| 707 |
+
if isinstance(image_grid_thw, list):
|
| 708 |
+
for t, h, w in image_grid_thw:
|
| 709 |
+
n = int(t) * (int(h) // merge) * (int(w) // merge)
|
| 710 |
+
tokens_per_image.append(n)
|
| 711 |
+
else:
|
| 712 |
+
for i in range(image_grid_thw.shape[0]):
|
| 713 |
+
t, h, w = image_grid_thw[i].tolist()
|
| 714 |
+
n = int(t) * (int(h) // merge) * (int(w) // merge)
|
| 715 |
+
tokens_per_image.append(n)
|
| 716 |
+
|
| 717 |
+
per_image_features = []
|
| 718 |
+
offset = 0
|
| 719 |
+
for n in tokens_per_image:
|
| 720 |
+
feat = image_features[offset : offset + n]
|
| 721 |
+
per_image_features.append(feat)
|
| 722 |
+
offset += n
|
| 723 |
+
|
| 724 |
+
return per_image_features
|
| 725 |
+
|
| 726 |
+
# ---- audio processing ---- #
|
| 727 |
+
|
| 728 |
+
def _parse_and_validate_audio_input(
|
| 729 |
+
self, **kwargs: object
|
| 730 |
+
) -> NanoAudioInputs | None:
|
| 731 |
+
input_features = kwargs.pop("input_features", None)
|
| 732 |
+
audio_embeds = kwargs.pop("audio_embeds", None)
|
| 733 |
+
feature_attention_mask = kwargs.pop("feature_attention_mask", None)
|
| 734 |
+
|
| 735 |
+
if input_features is None and audio_embeds is None:
|
| 736 |
+
return None
|
| 737 |
+
|
| 738 |
+
if audio_embeds is not None:
|
| 739 |
+
return NanoAudioEmbeddingInputs(
|
| 740 |
+
type="audio_embeds", audio_embeds=audio_embeds
|
| 741 |
+
)
|
| 742 |
+
|
| 743 |
+
return NanoAudioFeatureInputs(
|
| 744 |
+
type="audio_features",
|
| 745 |
+
input_features=input_features,
|
| 746 |
+
feature_attention_mask=feature_attention_mask,
|
| 747 |
+
)
|
| 748 |
+
|
| 749 |
+
def _process_audio_input(
|
| 750 |
+
self, audio_input: NanoAudioInputs
|
| 751 |
+
) -> torch.Tensor | tuple[torch.Tensor, ...]:
|
| 752 |
+
if audio_input["type"] == "audio_embeds":
|
| 753 |
+
return tuple(audio_input["audio_embeds"])
|
| 754 |
+
|
| 755 |
+
input_features = audio_input["input_features"]
|
| 756 |
+
feature_attention_mask = audio_input["feature_attention_mask"]
|
| 757 |
+
|
| 758 |
+
feature_lens = feature_attention_mask.sum(-1).long()
|
| 759 |
+
aftercnn_lens, output_lengths = (
|
| 760 |
+
self.audio_tower._get_feat_extract_output_lengths(feature_lens)
|
| 761 |
+
)
|
| 762 |
+
|
| 763 |
+
packed = input_features.permute(0, 2, 1)[feature_attention_mask.bool()].permute(1, 0)
|
| 764 |
+
|
| 765 |
+
audio_outputs = self.audio_tower(
|
| 766 |
+
packed, feature_lens=feature_lens, aftercnn_lens=aftercnn_lens,
|
| 767 |
+
)
|
| 768 |
+
audio_features = self.audio_projector(audio_outputs.last_hidden_state)
|
| 769 |
+
|
| 770 |
+
return torch.split(audio_features, output_lengths.tolist())
|
| 771 |
+
|
| 772 |
+
# ---- embed_multimodal ---- #
|
| 773 |
+
|
| 774 |
+
def embed_multimodal(self, **kwargs: object) -> MultiModalEmbeddings:
|
| 775 |
+
embeddings: list[torch.Tensor] = []
|
| 776 |
+
|
| 777 |
+
pixel_values = kwargs.pop("pixel_values", None)
|
| 778 |
+
image_grid_thw = kwargs.pop("image_grid_thw", None)
|
| 779 |
+
if pixel_values is not None and image_grid_thw is not None:
|
| 780 |
+
embeddings.extend(
|
| 781 |
+
self._process_image_input(pixel_values, image_grid_thw)
|
| 782 |
+
)
|
| 783 |
+
|
| 784 |
+
pixel_values_videos = kwargs.pop("pixel_values_videos", None)
|
| 785 |
+
video_grid_thw = kwargs.pop("video_grid_thw", None)
|
| 786 |
+
kwargs.pop("timestamps", None)
|
| 787 |
+
if pixel_values_videos is not None and video_grid_thw is not None:
|
| 788 |
+
embeddings.extend(
|
| 789 |
+
self._process_image_input(pixel_values_videos, video_grid_thw)
|
| 790 |
+
)
|
| 791 |
+
|
| 792 |
+
audio_input = self._parse_and_validate_audio_input(**kwargs)
|
| 793 |
+
if audio_input is not None:
|
| 794 |
+
self._pending_audio_in_batch = True
|
| 795 |
+
audio_embeds = self._process_audio_input(audio_input)
|
| 796 |
+
if isinstance(audio_embeds, tuple):
|
| 797 |
+
embeddings.extend(audio_embeds)
|
| 798 |
+
else:
|
| 799 |
+
embeddings.append(audio_embeds)
|
| 800 |
+
|
| 801 |
+
return embeddings if embeddings else []
|
| 802 |
+
|
| 803 |
+
# ---- forward ---- #
|
| 804 |
+
|
| 805 |
+
def forward(
|
| 806 |
+
self,
|
| 807 |
+
input_ids: torch.Tensor | None,
|
| 808 |
+
positions: torch.Tensor,
|
| 809 |
+
intermediate_tensors: IntermediateTensors | None = None,
|
| 810 |
+
inputs_embeds: torch.Tensor | None = None,
|
| 811 |
+
**kwargs: object,
|
| 812 |
+
) -> torch.Tensor | IntermediateTensors:
|
| 813 |
+
if intermediate_tensors is not None:
|
| 814 |
+
inputs_embeds = None
|
| 815 |
+
|
| 816 |
+
has_audio = self._pending_audio_in_batch
|
| 817 |
+
self._pending_audio_in_batch = False
|
| 818 |
+
|
| 819 |
+
hidden_states = self.language_model.model(
|
| 820 |
+
input_ids, positions, intermediate_tensors, inputs_embeds=inputs_embeds
|
| 821 |
+
)
|
| 822 |
+
hidden_states = self._apply_audio_alignment(
|
| 823 |
+
hidden_states, input_ids, positions, has_audio=has_audio
|
| 824 |
+
)
|
| 825 |
+
return hidden_states
|
| 826 |
+
|
| 827 |
+
def compute_logits(self, hidden_states: torch.Tensor) -> torch.Tensor | None:
|
| 828 |
+
return self.language_model.compute_logits(hidden_states)
|
| 829 |
+
|
| 830 |
+
# ---- weight loading ---- #
|
| 831 |
+
|
| 832 |
+
@staticmethod
|
| 833 |
+
def _remap_weights(
|
| 834 |
+
weights: Iterable[tuple[str, torch.Tensor]],
|
| 835 |
+
) -> Iterable[tuple[str, torch.Tensor]]:
|
| 836 |
+
for name, tensor in weights:
|
| 837 |
+
if name.startswith("language_model.") and not name.startswith(
|
| 838 |
+
"language_model.model."
|
| 839 |
+
) and not name.startswith("language_model.lm_head."):
|
| 840 |
+
name = "language_model.model." + name[len("language_model."):]
|
| 841 |
+
yield name, tensor
|
| 842 |
+
|
| 843 |
+
def load_weights(self, weights: Iterable[tuple[str, torch.Tensor]]) -> set[str]:
|
| 844 |
+
loader = AutoWeightsLoader(self)
|
| 845 |
+
return loader.load_weights(self._remap_weights(weights))
|
| 846 |
+
|
| 847 |
+
|
| 848 |
+
_IMAGE_TOKEN = "<image>"
|
| 849 |
+
_IMAGE_PLACEHOLDER = "<image>"
|
| 850 |
+
_VIDEO_PLACEHOLDER = "<image>"
|
| 851 |
+
_AUDIO_PLACEHOLDER = "<|audio_start|><|audio_pad|><|audio_end|>"
|
| 852 |
+
|
| 853 |
+
|
| 854 |
+
def _image_chat_prompt(text: str = "") -> str:
|
| 855 |
+
return f"<|im_start|>user\n<|vision_start|>{_IMAGE_TOKEN}<|vision_end|>{text}<|im_end|>\n"
|
| 856 |
+
|
| 857 |
+
|
| 858 |
+
def format_prompt(text: str = "", image=None, video=None, audio=None) -> dict:
|
| 859 |
+
"""Build a `llm.embed(...)` request dict for jina-embeddings-v5-omni-nano.
|
| 860 |
+
|
| 861 |
+
Inserts the model's vision/audio placeholder tokens for you so callers
|
| 862 |
+
don't need to spell them out.
|
| 863 |
+
|
| 864 |
+
For audio, also pass ``tokenization_kwargs={"add_special_tokens": False}``
|
| 865 |
+
to ``llm.embed`` so that LAST-token pooling lands on `<|audio_end|>` rather
|
| 866 |
+
than the tokenizer's auto-appended `<|end_of_text|>`.
|
| 867 |
+
"""
|
| 868 |
+
if image is not None and video is None and audio is None:
|
| 869 |
+
return {"prompt": _image_chat_prompt(text), "multi_modal_data": {"image": image}}
|
| 870 |
+
|
| 871 |
+
parts: list[str] = []
|
| 872 |
+
mm: dict = {}
|
| 873 |
+
if image is not None:
|
| 874 |
+
parts.append(_IMAGE_PLACEHOLDER)
|
| 875 |
+
mm["image"] = image
|
| 876 |
+
if video is not None:
|
| 877 |
+
parts.append(_VIDEO_PLACEHOLDER)
|
| 878 |
+
mm["video"] = video
|
| 879 |
+
if audio is not None:
|
| 880 |
+
parts.append(_AUDIO_PLACEHOLDER)
|
| 881 |
+
mm["audio"] = audio
|
| 882 |
+
req: dict = {"prompt": "".join(parts) + text}
|
| 883 |
+
if mm:
|
| 884 |
+
req["multi_modal_data"] = mm
|
| 885 |
+
return req
|
| 886 |
+
|
| 887 |
+
|
| 888 |
+
import sys as _sys
|
| 889 |
+
_sys.modules.setdefault("jina_v5_omni", _sys.modules[__name__])
|